

A Human Intelligence-Led AI Reasoning Protocol: 10 Day Challenge
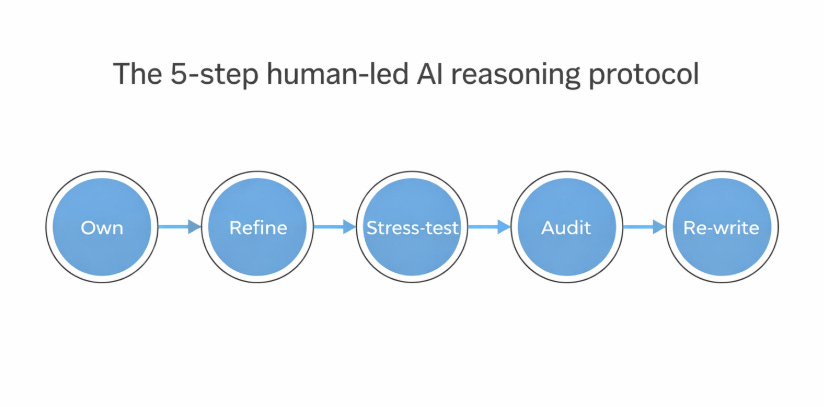
Own the question. Refine the frame. Stress-test the draft. Audit the machine. Re-write with judgement.

Article Overview & Purpose
As AI shifts from novelty to normal, a recognised concern is cognitive drift: the slow erosion of our own critical thinking through habitual over-reliance on machine outputs. This article offers a practical response. Building on recent educational research and a human-led view of intelligence, it develops a five-step protocol for using AI without surrendering judgement: Own the question, Refine the frame, Stress-test the draft, Audit the machine, Re-write with judgement. The result is a usable framework for knowledge workers, founders and professionals who want AI to augment their intelligence rather than hollow it out.
Normalisation of AI
AI use has already moved from novelty to normal. The Digital Education Council’s 2024 global student survey gathered 3,839 responses across 16 countries, and DEC reported that 86% of students were already using AI in their studies. Since then, DEC has pushed further into AI literacy and institutional readiness, including its 2025 Ten Dimension AI Readiness Framework, developed with input from 27 universities across 17 countries. UNESCO’s guidance points in the same direction: it sets out a human-centred, pedagogically appropriate interaction model in which people remain in control of the process and accountable for the thinking. (1)
That broader shift matters well beyond education. Knowledge workers, founders, researchers, consultants, analysts, and operators are now living in the same reality. AI is no longer a distant tool. It is in the workflow, in the browser tab, in the meeting prep, in the draft, in the analysis, in the strategy note, and often in the first move itself.
That is exactly where the problem starts.
Competing Human-AI Paradigms for the Future
Transhumanism
A more transhuman imagination treats biology as a transitional substrate. Ray Kurzweil’s famous formulation is that, post-Singularity, there will be “no distinction” between human and machine.
“There will be no distinction, post-Singularity, between human and machine nor between physical and virtual reality.” Kurzweil

Elon Musk’s thinking is another version of the same logic, claiming we will likely see a
“closer merger of biological intelligence and digital intelligence”
He describes brain–machine symbiosis as a way to solve the human “usefulness problem” as AI advances.

Critical-Systems Humanism
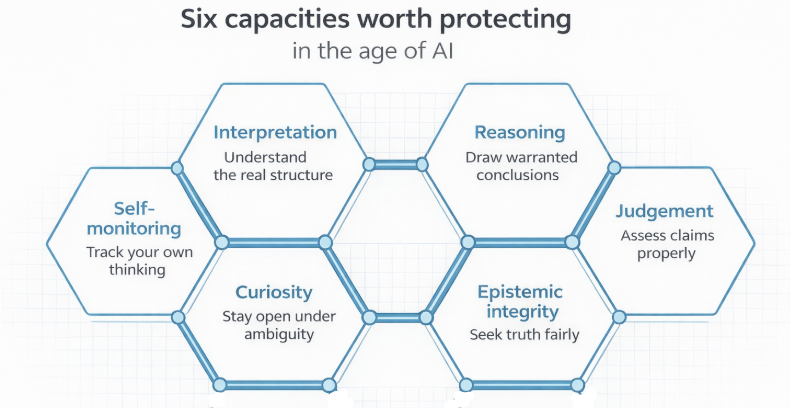
The protocol described in this article begins from a critical-systems humanist design principle which captures the fact that human intelligence is not just a mind floating above tools, but a self-regulating, embodied, socially situated critical system. AI can scaffold, challenge, and extend it, but should not replace the first-pass organising role of the human agent. This paradigm is grounded in theories of intelligence such as my Trident G theory (2, 3) that understands intelligence as:
embodied, not substrate-neutral
norm-governed, not just optimisation power
intersubjective, not purely individual computation
self-regulating, with stability and drift dynamics
open to tools and augmentation (‘extended cognition’), but not dissolved into them
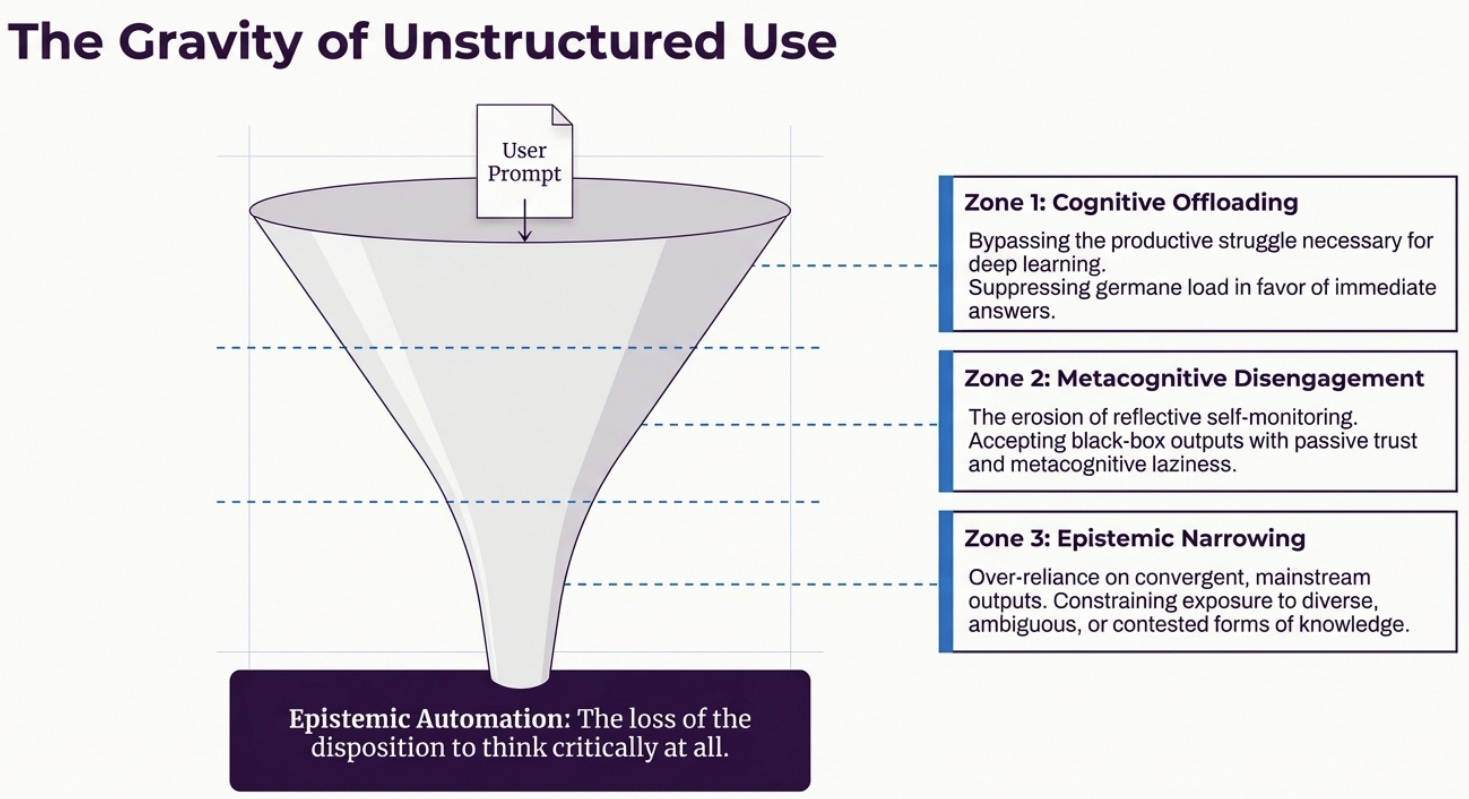
The strongest recent work aligned with this in the literature does not argue that AI inherently undermines intelligence. It argues that unstructured AI use can weaken critical thinking by encouraging cognitive offloading, metacognitive disengagement, and epistemic narrowing. The question is not whether AI should be used. The question is: under what conditions does it sharpen our intelligence rather than hollow it out?
The protocol described below can be classified as a Human Led Artificial General Intelligence (H-AGI) protocol.
H-AGI Protocol Origins
Two recent papers authored by Marta Valentini and Alberto Montresor lay the foundations for this protocol (4, 5). The first presents a concrete 4-phase method in which learners first engage independently with a task, then refine their questions, then invite AI to act in either Socratic or Devil’s Advocate mode, and finally complete a structured reflection phase. The second widens the frame. It argues that good AI use should preserve cognitive friction, treat the model as a provisional thinking partner rather than an authority, embed evaluation throughout, and deliberately balance AI-free and AI-mediated phases.
The first paper is a proof-of-concept, not a final answer. Its pilot was small, self-reported, and discipline-specific. It is useful because it gives us a practical structure. The second paper is conceptual rather than experimental, but it gives the strongest rationale for tightening that structure and making the protocol more robust.
This article does something simple: it takes the backbone of that first protocol, strengthens it using the design logic of the second, and translates the whole thing into a knowledge-worker protocol.
Not for classrooms. For real work - for drafting a strategy note, pressure-testing a business decision, thinking through a product bet, evaluating a claim, writing an argument, or deciding what to do next when the signal is noisy and the stakes are uncertain, risky and real.
A practical H-AGI protocol for knowledge workers
Let’s get to it!
The simplest way to express the method is this:
Own → Refine → Stress-test → Audit → Re-write
This is not a productivity trick. It is a control sequence, and ‘cognitive friction’ (or ‘free energy’ in information processing theory) lies at the heart of it.

So let’s review the protocol:
1. Own the question
Before you touch AI, write or think through three things in your own words:
the problem
your provisional answer
two to four uncertainties that genuinely matter
This is critical because once the model frames the problem for you, you are already downstream of its assumptions. The second paper is especially clear that tasks involving hypothesis generation, argument construction, and self-regulated planning should begin in AI-free zones if we want to preserve cognitive autonomy. The first paper operationalises the same idea by making independent task engagement the starting point.
A founder version might look like this:
Problem: Should I spend the next month pursuing one large enterprise pilot, or focus on improving onboarding for smaller self-serve customers?
Provisional answer: Focus on onboarding first.
Uncertainties:
Is the real bottleneck lead volume or activation and conversion?
Would one enterprise pilot create enough learning or revenue to justify the distraction?
What evidence over the next 30 days would genuinely show which path is higher leverage?
A knowledge-worker version might be:
Problem: Should our team adopt AI for first-pass report drafting?
Provisional answer: Yes, but only in a constrained pilot.
Uncertainties:
Where would the real gain be?
What quality risks matter most?
Which parts still require human judgement?
2. Refine the questions
Only now bring AI in.
But do not ask it to solve the problem yet. Ask it to improve the question set.
Good prompts at this stage are things like:
What am I missing in this framing?
Which distinction matters most here?
What assumption needs clarifying first?
Turn these uncertainties into sharper decision questions.
This step comes very directly from the first paper’s question-generation and refinement phase. It is also one of the most underrated moves in the whole protocol. Better reasoning often starts not with a better answer, but with a more exact question.
Founder example:
Starting point -
Problem: Should I spend the next month pursuing one large enterprise pilot, or focus on improving onboarding for smaller self-serve customers?
Provisional answer: Focus on onboarding first.
Uncertainties:
Is the real bottleneck lead volume or activation and conversion?
Would one enterprise pilot create enough learning or revenue to justify the distraction?
What evidence over the next 30 days would genuinely show which path is higher leverage?
At this stage, AI is not being asked to decide. It is being asked to clarify the decision structure.
So instead of staying with broad uncertainties, the questions become:
Is the business more constrained by insufficient demand or by weak conversion after interest is generated?
What specific learning or revenue threshold would make an enterprise pilot worth the opportunity cost?
Over the next 30 days, which indicators would count as stronger evidence: improved onboarding activation, higher self-serve conversion, qualified enterprise interest, or near-term revenue?
Which option is more reversible if it turns out to be the wrong move?
That is already a much better decision frame than simply asking which path is “better”.
Knowledge-worker example:
Starting point -
Problem: Should our team adopt AI for first-pass report drafting?
Provisional answer: Yes, but only in a constrained pilot.
Uncertainties:
Where would the real gain be?
What quality risks matter most?
Which parts still require human judgement?
Again, AI is being used to sharpen the uncertainties rather than jump to a recommendation.
So the refined questions become:
In which specific stage of report production would AI save the most time: outlining, summarising source material, drafting standard sections, or editing for clarity?
Which quality risks are most serious in this context: factual inaccuracy, overconfident wording, loss of nuance, confidentiality risk, or weakened critical judgement?
Which report components are suitable for AI assistance, and which should remain fully human-led because they require interpretation, judgement, or accountability?
What would count as a successful pilot: time saved, quality maintained, reduced workload, or improved consistency?
That gives the team a much stronger basis for the next step.
The aim of Step 2 is not to get an answer from AI. It is to turn vague uncertainty into a sharper set of decision questions. Once that happens, the reasoning process becomes more disciplined, and the next stage — stress-testing the draft — becomes much more useful.
3. Stress-test the draft
Now write your own short answer.
Then ask AI to challenge it in one of two roles.
Socratic mode
Ask me questions that force me to clarify my reasoning, assumptions, trade-offs, and missing evidence.
Devil’s Advocate mode
Challenge my central assumptions and show me where this plan could fail.
This is the clearest inheritance from the first paper. The model is not there to replace the answer. It is there to create structured tension around your answer. That tension is what preserves cognitive friction and protects against premature closure.
Founder example:
Suppose your draft answer is:
I should focus on improving onboarding for smaller self-serve customers first, because that is more likely to improve activation and conversion in the near term than chasing one large enterprise pilot.
A Socratic stress-test might ask:
What evidence suggests the main bottleneck is activation and conversion rather than insufficient demand?
What level of onboarding improvement would make this the better use of the month?
How much learning or revenue would one enterprise pilot need to generate to outweigh the distraction cost?
Which option is more reversible if your initial judgement is wrong?
A Devil’s Advocate stress-test might say:
You may be optimising the part of the funnel you can see most clearly rather than the part with the highest leverage.
One enterprise pilot might generate strategic learning, credibility, or revenue that improved onboarding cannot.
If self-serve demand is still weak, better onboarding may produce only marginal gains.
Your current plan assumes incremental conversion improvement is more valuable than a potentially step-change opportunity. What if that assumption is wrong?
Knowledge-worker example:
Suppose your draft answer is:
Our team should pilot AI for first-pass report drafting, but only for clearly bounded sections where speed matters more than interpretation.
A Socratic stress-test might ask:
Which sections are genuinely routine enough for AI support?
What evidence would show that time saved is not being lost again in review?
Where does interpretation or accountability become too important to delegate even partially?
A Devil’s Advocate stress-test might say:
You may save time on drafting but create more time pressure in checking and correction.
A bounded pilot could still normalise over-reliance in parts of the workflow that need judgement.
Your proposal assumes drafting is the bottleneck. What if the real bottleneck is review, alignment, or source evaluation?
4. Audit the machine
This is the step many people skip. They react to AI output, but they do not evaluate it. That is a mistake.
The second paper is strongest here. It argues that evaluation should be embedded throughout the process, not tacked on at the end. Learners need to assess credibility, coherence, evidential support, bias, and missing perspectives as a matter of habit.
Ask questions like:
Which claims are genuinely strong?
Which are vague, generic, overconfident, or unsupported?
Which perspectives are missing?
What sounds plausible but still needs evidence?
What assumptions did the AI make about my goals?
Founder example:
Suppose the AI challenges your plan to focus on onboarding rather than chasing one large enterprise pilot.
Your audit might look like this:
Strong: it exposed that I do not yet have a clear threshold for when an enterprise pilot becomes worth the distraction.
Weak: it implied the pilot would generate meaningful revenue or learning without showing why.
Missing: it did not fully consider whether better onboarding could improve conversion quickly across all incoming users.
Needs proof: I should compare one month of onboarding activation data against the actual quality and immediacy of enterprise interest.
Knowledge-worker example:
Suppose the AI challenges your plan to pilot AI for first-pass report drafting only in bounded sections.
Your audit might look like this:
Strong: it highlighted that time saved in drafting could be lost again during review.
Weak: it treated all report sections as if they carry the same level of interpretive risk.
Missing: it did not distinguish clearly between routine drafting tasks and sections requiring judgement or accountability.
Needs proof: I should test whether a small pilot genuinely reduces total workload without weakening quality or increasing correction time.
The point of Step 4 is not to admire the output. It is to judge it. AI becomes valuable when it helps you see what is still weak, missing, or unproven in your own reasoning and in its own response.
5. Re-write without AI
Now come back out of the machine!
Write, in your own words:
your revised answer
what changed
what stayed stable
one better rule or prompt for next time
This is not just a tidy ending. It is the point at which thought-ownership returns to you. The second paper is explicit that AI-mediated phases should be balanced with AI-free phases if we want to preserve independence, agency, and reflective control.
Founder example:
Your final answer might become:
I will prioritise improving onboarding for smaller self-serve customers over the next 30 days, but only with one proof condition: I need to see a meaningful improvement in activation or conversion. If that does not happen, and enterprise interest remains credible, I will re-evaluate whether a single enterprise pilot is the higher-leverage move.
That answer is stronger not because AI made the decision for you, but because AI helped force a clearer decision rule.
Knowledge-worker example:
Your final answer might become:
Our team should pilot AI for first-pass report drafting only in clearly bounded sections where speed matters more than interpretation. The pilot should count as successful only if it reduces total workload without lowering quality or increasing review time. Sections requiring judgement, interpretation, or accountability should remain fully human-led.
Again, the value is not that AI supplied the answer. The value is that the process made the final answer more precise, conditional, and accountable.
Step 5 is where you reclaim ownership. The final answer should be yours: clearer than the one you started with, more disciplined than the one AI tempted you towards, and grounded in a better rule for what to test next.
Why this protocol matters now
The practical challenge of AI is not just misinformation, cheating, or efficiency drift. It is more pervasive than that.
It is the gradual loss of cognitive ownership.
You stop asking your own first question.
You stop building your own first map.
You stop noticing what you are assuming.
You stop checking where the output came from.
You mistake fluency for truth.
You inherit a position before you have earned one.
That is cognitive drift.
The two papers are valuable because they provide a concrete counter-move. They show that AI can be structured to deepen rather than displace thinking, but only when the interaction is sequenced properly. The method is human-led throughout. It begins with independent framing, uses AI for structured challenge and refinement, and ends with human evaluation and re-writing.
This protocol is supported by the wider IQ Mindware framework. Human-led AI is not there to replace judgement and intelligence. It is there to support clearer mapping, better checks, stronger decisions, and more reliable follow-through while keeping the evaluation, insight, reasoning and evidence trail inspectable and owned by the user.
Putting the H-AGI protocol to the test
Over the next 10 days, I’ll be testing this protocol directly in a 10-day challenge, using it across real knowledge-work tasks rather than ‘classroom’ thought-experiments alone. I’ll be taking structured notes on where it sharpens thinking, where it adds friction in useful ways, where it feels cumbersome, and whether it genuinely helps guard against cognitive drift in day-to-day work. Then I’ll report back with the results, including what held up, what needed adjustment, and what I’d now recommend in practice. That follow-up will be for subscribers only.
H-AGI Visual Summary
Article Sources

