



Beyond Brain Training Placebo Effects: Foundational Principles for Far Transfer
Bridging Automaticity and Strategy: A New Approach to Unlocking Far Transfer in Brain Training
In my previous article I summarised the IQ-increasing benefits of training with mainstream brain training apps via the placebo effect, summarised in this explainer diagram, drawing from the work of Wager & Jung [article].

This argument concluded that while mainstream brain training helps with the performance mindset and via this mechanism helps cognitive performance, it does not result in far transfer - the development of generalisable cognitive skills that make us smarter.
The Hard Problem for Brain Training: Far Transfer
To quote Gathercole and colleagues [article]:
Performance on many working memory (WM) tasks can be improved by training. However, the benefits of that training rarely transfer to other activities that also depend on WM. Why is this, and what conditions give rise to transfer?
This argument generalises to other cognitive functions such as attention focus and flexibility, reasoning ability, and so on.
While near transfer is well established [article], there is little evidence of useful far transfer - of training with a game designed to intensively exercise a core capacity like working memory, and then seeing practice gains transfer to useful real-world tasks that depend on working memory - such as reasoning, problem solving or decision-making. Why is the core capacity that is trained so ‘sticky’ and locked into a particular training task?
In this article I’m going to address this hard problem by developing a robust, evidence-based framework that can explain:
Why we get near transfer in mainstream brain training but not far transfer
What conditions that are needed for successful far transfer in brain training
To address these questions we need to introduce some core concepts that are well-established in the cognitive neuroscience literature.
Near Transfer
Near transfer occurs when the training task and the untrained task share many similar perceptual features or task processes. It involves the application of the same cognitive routine or skill to new but similar tasks, where both tasks require similar cognitive demands or share common structures.
In cognitive psychology, transfer is more likely to occur when tasks share the same paradigms, such as complex span or backward span. For instance, if training involves verbal serial recall, the improvements may transfer to similar tasks like digit span recall, where the cognitive routine of maintaining and recalling information in order is still required.
Far Transfer
Far transfer occurs when the training task and the untrained task share fewer features or less similar structures, and the cognitive routine developed during training must be adapted to suit novel or more complex tasks. Far transfer is rarer because it depends on the flexibility of the newly developed cognitive routine and whether it can be applied across different tasks that have differing cognitive demands.
Far transfer would occur when the higher-order routines developed during training on tasks like the dual n-back can be applied to a new and different task that still shares some strategic demands (e.g., managing interference or updating memory), but is otherwise different in structure, such as transferring from n-back training to tasks that require general updating skills but differ in their surface-level characteristics.
Skills
Skills are specific abilities that are honed through repeated practice, leading to automation and increased efficiency. As skills become more refined, they require less conscious effort and control, freeing up limited cognitive resources. The main characteristic of a skill is that it becomes efficient over time, reducing the cognitive load - the amount of mental effort and working memory needed to complete a task. This means the brain can perform the task (such as typing or basic mental arithmetic) automatically or with minimal conscious thought.
In other words, once a skill is well developed, it relies less on limited capacity working memory, attention, and cognitive control, allowing for more fluid and effortless performance within familiar contexts. This reduction in cognitive load allows the brain to allocate its resources elsewhere, supporting more complex thought processes or handling additional tasks simultaneously.
Strategies (Mindware) & Cognitive Load
Strategies - also called mindware -are higher-level methods, procedures, or routines used to solve problems or achieve goals. Applying strategies involves flexibility and adaptation, meaning that strategies can be applied in various contexts depending on the demands of the task. Strategies are deliberate and rely on cognitive control, requiring us to assess the situation, select an appropriate method, and adjust our approach as needed.
Strategies inherently involve a higher cognitive load, as they demand the active use of working memory, attention control, and other high-level cognitive processes. Cognitive load refers to the mental effort required to process information and manage tasks, and it increases with the complexity and novelty of the situation. The ability to employ strategies flexibly and effectively depends on our overall cognitive capacity and our ability to manage this increased cognitive load without becoming overwhelmed. Successful strategy use, therefore, requires balancing the cognitive load to ensure that working memory and attention are optimally allocated to handle the demands of the task.
Cognitive Routines: Bridging Skills and Strategies
Gathercole and colleagues [article] introduce the term ‘cognitive routines,’ which serve as the bridge between specific skills and flexible strategies, playing a crucial role in adapting learned abilities to novel situations. Cognitive routines are structured sequences of processes required to perform a task. Initially, these routines are resource-intensive, demanding deliberate cognitive effort to manage and coordinate the task's components. However, with practice, they become more autonomous, allowing for more efficient task execution.

These routines exist on a hierarchical spectrum, beginning with task-specific skills that are automatic, efficient, but limited in scope. For example, a cognitive routine might start as a simple rehearsal process in a memory task, involving the repetition of items to prevent forgetting. As these routines become more abstract and complex, they evolve into more generalisable strategies that can be applied across different contexts, such as chunking information. This abstraction allows the routine to be adapted to different tasks that share structural similarities, facilitating near transfer. However, the generalisability of these strategies is bounded by the structure of the routine, meaning their effectiveness is limited to tasks with similar demands.
The Successor Representation (SR) framework plays a crucial role in enabling these cognitive routines to retain learned sequences and patterns, which can then be flexibly applied to new tasks when combined with model-based reasoning. This dual capacity for stability (through retention) and adaptability (through integration with model-based strategies) is key to understanding how cognitive routines can support far transfer.
Systematicity and High-Level Cognitive Routines
Systematicity plays a key role in the development and application of high-level cognitive routines. As routines evolve from task-specific skills to more generalisable strategies, systematicity ensures these routines are organised into coherent, relational frameworks. The principle of systematicity - where elements of a cognitive routine are interconnected in a structured, relational system - enhances the effectiveness and flexibility of the routine.
In educational psychology, a highly systematic strategy might involve not just the rote memorisation of facts but the integration of those facts into a broader conceptual framework that supports understanding and application across various contexts. This systematic organisation makes high-level cognitive routines more robust and versatile, allowing them to be more easily adapted to new tasks that require similar underlying processes. In this way, systematicity supports the transition of routines into strategies, reinforcing their applicability across different domains while ensuring their effectiveness is maximised within the constraints of their structure.
The SR framework aids in maintaining systematicity by encoding predictive representations that link specific actions to future states. This systematic encoding allows routines to be both stable and adaptable, ensuring they can be applied to different tasks that share underlying structural similarities, thus supporting far transfer.
Model-Free vs. Model-Based Learning
In model-free learning, skilled actions are based on previously experienced rewards, without the need for understanding the underlying structure of the task - no ‘world model’ is constructed. This approach is computationally simpler but less flexible. It is often associated with habitual actions driven by past reinforcement, relying on the Reward Prediction Error (RPE) theory of dopamine, which is heavily processed in regions like the ventral striatum.
Model-free learning involves the dopaminergic-striatal system, particularly the ventral striatum and regions of the basal ganglia, where habitual actions are formed. These regions rely on dopaminergic RPE signals to reinforce actions that have previously led to rewards. These systems are good for automating behaviour for efficiency but lack the capacity to adapt flexibly to new, unlearned contexts.
Model-based learning, by contrast, involves constructing a ‘world model’ that simulates the consequences of actions, allowing for flexible decision-making based on forward-looking computations. This system evaluates actions by predicting their future outcomes, considering how different sequences of actions might unfold.
Model-based learning depends on the prefrontal cortex, particularly the dorsolateral prefrontal cortex (dlPFC), to simulate potential future states and outcomes. The hippocampus is also implicated in model-based processes due to its role in cognitive mapping and spatial reasoning. Model-based learning relies on prefrontal-hippocampal-striatal circuits, which allow for goal-directed behaviour and adaptation to changes in the environment or task goals.
Hybrid Learning and the Successor Representation (SR) Framework
Recent advances in cognitive neuroscience propose hybrid predictive coding accounts that bridge the gap between model-free and model-based decision-making and learning. [article 1, article 2]

The Successor Representation (SR) framework, as highlighted by Evan Russek and colleagues, provides a central role for neurons that encode predictive representations anticipating future states based on previous experience. Unlike model-free systems that only store value estimates of specific actions, the SR framework stores a predictive map of future situations (states), allowing for more flexible decision-making without the computational burden of fully simulating possible outcomes, as required in model-based learning.
For example, when navigating a new city with a layout similar to one previously navigated, the SR framework allows you to use stored predictions from the familiar city to infer likely outcomes in the new city (such as a bank is likely to be near the city centre). This predictive knowledge enables flexible adaptation to new environments without needing to relearn everything from scratch, offering more flexibility than purely model-free strategies.
Learning Neurobiology and the SR Framework
The hybrid Successor Representation (SR) system bridges the efficiency of model-free learning with the flexibility of model-based learning via shared neural circuits. These include the ventral striatum, dopaminergic midbrain regions, the hippocampus and the dorsolateral prefrontal cortex (dlPFC). These circuits enable the SR to predict future states using past experiences, supporting both habitual (model-free) and goal-directed (model-based) actions.
Dopamine neurons in the midbrain - specifically the ventral tegmental area (VTA) and substantia nigra - encode Reward Prediction Errors (RPEs), which are discrepancies between expected and received rewards. These RPE signals are transmitted to the ventral striatum, where they help update the predictive state representations within the SR framework. When an action leads to an unexpected reward (positive RPE), the SR adjusts its predictions for future states, enhancing the flexibility needed for effective decision-making. Conversely, when outcomes are worse than expected (negative RPE), the SR is refined to reduce the likelihood of repeating the action in similar contexts.
In addition to RPEs, the SR framework may also respond to Epistemic Prediction Errors (EPEs) - discrepancies between expected and observed information about the environment. These EPEs drive the updating of cognitive models to reduce uncertainty, thereby supporting knowledge-based exploration and learning. This dual sensitivity to both reward-based and knowledge-based prediction errors allows the SR framework to remain adaptable, continuously updating its predictive map of future states in response to environmental and informational feedback.
The hippocampus plays a vital role in the SR framework by facilitating spatial navigation and the formation of cognitive maps. These cognitive maps are essential for the brain to anticipate the outcomes of different actions by mapping out potential successor states. This predictive capability, supported by hippocampal involvement, is crucial for flexible decision-making and for adapting strategies to novel or complex scenarios. The integration of spatial and contextual information with predictions from the prefrontal cortex allows for more efficient computation of future state values, thereby supporting far transfer by making these predictive representations adaptable across different contexts.
Cortico-striatal loops, connecting the dorsomedial striatum to regions of the prefrontal cortex, further support the integration of model-free and model-based processes. By tapping into SR representations stored in the prefrontal cortex, these loops guide decision-making in tasks that require both automaticity and strategic flexibility. The hippocampus and cortico-striatal loops act as bridges, allowing SR representations and cognitive maps to be integrated into more complex, goal-directed behaviours, thereby facilitating far transfer across a variety of cognitive tasks.
Skills, Strategies, and the SR Framework
Skills are specific abilities honed through repeated practice, leading to automation and increased efficiency. This process relies heavily on model-free learning processes, where actions are selected based on rewards they have previously produced, rather than on a forward-looking model of the world.
Strategies (or mindware) are higher-level, flexible methods used to solve problems and achieve goals. They require cognitive control, the ability to adapt to new situations, and often rely on a more deliberate, effortful approach. Model-based learning is crucial for strategies, as it involves constructing a mental model of the environment to simulate and evaluate different possible outcomes.
Cognitive routines are hypothesised to bridge the gap between specific skills and flexible strategies. Depending on their level of abstraction and systematicity, these routines may be more automatic and stimulus-response-based or strategic and generalisable to contexts sharing the same higher-level procedural structure. The Successor Representation (SR) framework serves as an intermediary between model-free and model-based systems. SR encodes the expected future states based on current actions, providing a flexible predictive model that can guide decision-making without the full computational load of model-based learning. Cognitive maps, supported by the SR framework, allow these routines to generalise and adapt across different contexts by predicting future states based on past experiences, thereby supporting both stability and adaptability in decision-making processes and facilitating far transfer.
General Intelligence
Raymond Cattell’s distinction between crystallised intelligence (Gc) and fluid intelligence (Gf) provides a helpful framework for understanding the roles of skills and strategies in general intelligence.
Crystallised Intelligence (Gc)
Crystallised intelligence refers to the accumulation of knowledge and skills acquired through experience and education. These learned abilities are stable and context-specific, often requiring little cognitive effort to apply once they are well-practiced. Skills which become automated over time through repeated practice are at the core of crystallised intelligence. They allow for efficient performance in familiar tasks because the brain no longer needs to expend significant cognitive resources, such as working memory or attention, to execute them.
Fluid Intelligence (Gf)
Fluid intelligence is the ability to reason, abstract concepts, and solve novel, complex problems. This form of intelligence is closely tied to strategic control - deplying strategies flexibly in adaptive task management. Unlike skills, which focus on efficiency, strategies require the capacity to manage cognitive load effectively by deploying working memory, attention control, and problem-solving abilities in diverse and unfamiliar contexts. Fluid intelligence enables us to devise and adjust strategies dynamically, helping us tackle novel challenges where using learned skills in familiar contexts is not enough.
Brain Network Basis of General Intelligence
As reviewed by Rong Wang and colleagues in this article, brain networks supporting intelligence are hierarchically organised into segregated and integrated modules.

Segregation in Modules Supports Specialisation
Segregated brain networks are those that operate relatively independently and focus on specific functions or cognitive tasks. These networks support the efficient processing of well-practiced tasks supporting crystallised intelligence (Gc). The modularisation of brain functions through segregation allows these specialised areas to operate optimally without interference from other processes.
Brain imaging research by Karolina Finc and colleagues has shown that working memory routines trained by the dual n-back can themselves become automated and increasingly modular through neuroplasticity change over a period of 4-6 weeks, training half an hour each day. [article]
Integration Across Modules Supports Flexibility
Integrated brain networks, on the other hand, facilitate communication between specialised modules, allowing the brain to coordinate across multiple domains. This integration is essential for flexibility, especially in tasks that require fluid intelligence (Gf), such as problem-solving and adapting to new and complex situations. Integration enables the brain to dynamically reconfigure itself, accessing and coordinating information from various segregated modules to meet new and complex cognitive demands.

Balance for Cognitive Efficiency and Flexibility
Rong Wang and colleagues argue that a balance between segregation and integration is important for general intelligence because it allows the brain to optimise both efficiency and flexibility. Too much segregation leads to highly specialised modules that may be very efficient at handling specific tasks but lack the ability to adapt to new or complex demands. This can result in rigid cognitive processing, making it difficult for the brain to handle novel tasks that require integration across domains. Too much integration, on the other hand, is metabolically costly and can lead to inefficient processing, as too many networks are involved in tasks that do not require such broad coordination. This can result in noisy ‘crosstalk’ and slower processing times, with reduced efficiency in task performance.
For higher levels of intelligence, the brain needs to dynamically reconfigure (or ‘tune’) its networks depending on the task at hand. A balance between brain segregation and integration ensures that the brain can shift between these two modes of functioning as needed, supporting both routine processing (crystallised intelligence) and adaptive, flexible thinking (fluid intelligence). Operating near this so-called critical point allows the brain to dynamically reconfigure itself, shifting between more segregated networks for routine tasks and more integrated networks for complex, novel challenges. This balance ensures that the brain can efficiently manage both familiar and new demands, thus supporting both routine processing and adaptive cognitive flexibility.
Recap
Skills are essentially about increasing efficiency within a given task. As they become more refined, they operate with minimal cognitive load, reflecting the brain’s ability to optimise performance by automating tasks and reducing the need for attention control or working memory. These efficient, well-practiced skills contribute to crystallised intelligence (Gc), where knowledge and learned abilities are applied effortlessly in familiar contexts.
On the other hand, strategies function for flexibility and adaptation. They rely on cognitive capacity, drawing from working memory, attention control, fluid recall, and reasoning ability to manage task complexity and cognitive load in novel or complex situations. Strategies support fluid intelligence (Gf) by enabling us to apply general rules or methods across different contexts, allowing for effective problem-solving and decision-making in unfamiliar situations. While skills aim for automation, strategies thrive on situational analysis and adaptability, making them essential for handling tasks that require higher-order thinking and creative solutions.
Brain networks underlying these cognitive processes are hierarchically organised, with segregated modules supporting specialised tasks (and thereby contributing to crystallised intelligence) and integrated networks facilitating the coordination of these modules for adaptive, flexible thinking (and thereby supporting fluid intelligence). However, for the brain to function optimally across different types of tasks, it must maintain a balance between segregation and integration - a state often referred to as brain criticality.
1. Why do we get Near Transfer in Mainstream Brain Training but not Far Transfer?
Near transfer occurs when cognitive tasks share similar features or processes, allowing learned skills or routines to be applied to new but structurally similar tasks. Near transfer is clearly evident in mainstream brain training programs that engage long-term neuroplasticity over several weeks of practice. [article]
Mainstream working memory (WM) training, such as the dual n-back task, likely engages both model-free learning and SR processes. Through repeated practice, individuals develop automatic routines for updating information, recalling stimuli, and managing interference. These routines are encoded as cognitive habits, which are supported by the SR framework's predictive coding. The SR system allows these habits to be effectively applied to other tasks with similar cognitive demands, leading to near transfer.
The hybrid SR system is particularly effective in facilitating near transfer because it encodes predictive state representations that allow the brain to anticipate future outcomes based on past experiences. These predictive maps are refined through practice, enabling the SR system to generalise learned skills across tasks that share underlying cognitive structures. This allows for smooth and efficient near transfer, where the same cognitive routines developed during training can be applied to tasks with similar demands, such as complex span tasks that involve comparable memory processes.
However, while SR learning supports the generalisation of routines across similar tasks, it does so within a bounded cognitive domain. The predictive state representations formed by the SR framework are optimised for tasks that share similar structures. This is why near transfer is commonly observed in mainstream working memory training, but far transfer - where skills need to be applied to tasks with different or more complex structures - is less frequent. Far transfer requires additional engagement of model-based processes and higher-order strategies that are not incorporated in mainstream brain training.
2. What Conditions are Needed for Successful Far Transfer?
Far transfer in brain training involves the application of learned skills or routines to tasks that differ significantly in structure or demands from those initially trained. Achieving far transfer requires a more sophisticated interplay of cognitive processes, where the cognitive system must adapt learned routines to new and varied contexts. Understanding cognitive neuroscience mechanisms hypothesised to underpin far transfer can inform the design of training interventions that effectively promote this broader application of skills.

Far Transfer Principle 1: Integrating Model-Free Skill Learning with Model-Based Mindware Applicaiton
Achieving far transfer in brain training is hypothesised to rely on the integration of multiple learning systems, including model-free learning, hybrid Successor Representation (SR) frameworks, and model-based strategies, or 'mindware.'
Model-free learning plays a critical role in the initial stages of training by automating cognitive routines through repeated exposure to specific tasks. This process allows for the efficient execution of these routines with minimal cognitive load and effort, particularly in tasks that involve working memory. Model-free learning systems reinforce habitual and highly-practiced responses based on past rewards, enabling the development of automatic, efficient behaviours.
However, while model-free learning optimises performance in familiar contexts, it is the SR coding framework that bridges the gap between model-free and model-based learning. The SR framework extends beyond mere habit formation by encoding predictive state representations in the form of cognitive maps that generalise learned routines based on past experiences. These predictive representations help the brain anticipate future outcomes, offering greater flexibility than traditional model-free systems. [article]
Hippocampal Cognitive Maps and Working Memory Gating
Cognitive maps encoded in the hippocampus are fundamental for creating predictive representations that help the brain navigate both familiar and novel contexts. These maps allow the brain to organize and anticipate the outcomes of different actions based on past experiences, thereby playing a crucial role in both routine and adaptive behaviours.
However, cognitive maps are not static. They are continually modulated and generalised by the prefrontal cortex (PFC), which plays a crucial role in gating working memory. The PFC's gating mechanisms selectively determine which aspects of these hippocampal cognitive maps are retained and deployed in decision-making processes. This selective filtering ensures that only the most salient information is maintained in working memory, facilitating the effective integration of model-free routines with model-based strategies.
As tasks are repeated and become more familiar, the brain transitions from relying on these cognitive maps to developing more automatic, model-free routines. These routines, encoded through reinforcement learning, allow for efficient and habitual responses to familiar situations. However, the predictive cognitive maps continue to play a crucial role even as behaviours become automatic. They enable the brain to adapt these model-free routines to new and varying contexts, providing the flexibility necessary for far transfer.
When combined with model-based reasoning - which involves forward-looking computations and cognitive control - these predictive cognitive maps allow the cognitive system to flexibly adapt learned routines to novel tasks. This dual approach- harnessing the efficiency of model-free learning while maintaining the flexibility provided by SR-based cognitive maps and model-based strategies - is essential for facilitating far transfer, where skills and knowledge are applied across a broad range of different and complex contexts. [article 1, article 2, article 3]
Linking Far Transfer to General Intelligence
The mechanisms supporting successful far transfer in brain training are closely related to the balance between crystallised and fluid intelligence, as well as the brain’s ability to dynamically reconfigure its networks through brain criticality.
Crystallised intelligence (Gc), associated with the automation of skills through model-free learning, aligns with the development of automatic, efficient cognitive routines. These routines, supported by segregated brain networks, allow for the efficient execution of familiar tasks with minimal cognitive effort.
Fluid intelligence (Gf), on the other hand, reflects the capacity for flexible, adaptive thinking, which is crucial for applying learned routines to novel and complex tasks - an essential component of far transfer. This adaptability is supported by integrated brain networks that facilitate the coordination of different cognitive domains through model-based strategies. Central to this process is the hippocampus, which plays a critical role in fluid intelligence by encoding cognitive maps. These cognitive maps, especially those formed in the CA1 subfield of the hippocampus, enable the brain to generalise learned information to new contexts by providing a structured representation of possible future states. [article]
Integration with WM Gating and Cognitive Maps
The PFC’s gating mechanisms interact with hippocampal cognitive maps to enables the selective retrieval and application of relevant information in new contexts. This interaction supports the SR coding framework by ensuring that only the most salient information is used to guide decision-making and problem-solving. The ability to generalise and adapt learned routines across different domains is thus strengthened by the dynamic interplay between the PFC and hippocampus, which together balance the need for stability (through cognitive maps) and flexibility (through WM gating). [article]
The Successor Representation (SR) framework bridges these two aspects of intelligence by allowing learned sequences to be retained and flexibly applied to new contexts, with the hippocampus contributing significantly to the creation and maintenance of the cognitive maps that underpin this flexibility. These maps enable the brain to efficiently navigate between known and novel situations, supporting both the efficient processing required for Gc and the adaptive flexibility characteristic of Gf. So achieving far transfer in brain training not only involves the development of efficient, automatic routines but also requires the integration of these routines with higher-order cognitive strategies, supported by hippocampal cognitive maps and PFC-mediated WM gating. This integration mirrors the dynamic balance between segregation and integration that underlies general intelligence, ensuring that skills can be adapted and applied across a broad range of cognitive tasks and contexts.
Cognitive Neuroscience Mechanisms
The following mechanisms are highlighted based on research such as: article 1, article 2, article 3.
Adaptive Learning and Modulation of Prediction Horizons
The Successor Representation (SR) framework can be enhanced through adaptive learning processes that modulate the predictive horizons of the cognitive system. ‘Predictive horizons’ refers to the ‘distance’ into the future (in terms of time or potential outcomes) that the brain can predict or prepare for, using existing knowledge. Research highlights that cognitive maps play a vital role in this modulation. [article]
Working memory (WM) gating mechanisms in the prefrontal cortex (PFC) also play a critical role, determining which aspects of these cognitive maps are retained and applied in working memory during decision-making processes. These combined mechanisms allow for the dynamic adjustment of predictive horizons, enabling the brain to seamlessly transition between different levels of abstraction and timescales. This flexibility is crucial when applying learned routines to novel contexts, as it supports the transition from model-free to model-based processes by generalising experiences across different but structurally similar tasks.
For far transfer to occur, training interventions must incorporate tasks that enable the dynamic modulation of these predictive horizons, allowing the cognitive system to flexibly apply learned skills in new and varied contexts. The role of cognitive maps is crucial as they provide the structural basis for this flexibility. Moreover, the WM gating mechanisms ensure that only relevant information from these cognitive maps is used, preventing cognitive overload and facilitating efficient decision-making and problem solving. Incremental learning is vital here, where tasks gradually increase in complexity, enabling the cognitive system to systematically build on previous learning while relying on consolidated cognitive maps. This approach ensures that the cognitive system is not overwhelmed but progressively develops the ability to handle more complex, flexible tasks.
Integration of Reward Prediction Errors (RPEs) and Epistemic Prediction Errors (EPEs)
RPEs and EPEs are vital in the continuous refinement of cognitive models. Cognitive maps rely on these error signals to become more adaptable and robust. Working Memory (WM) gating mechanisms in the prefrontal cortex play a crucial role by filtering and prioritising these errors, ensuring that only the most relevant discrepancies are retained and used to update cognitive models effectively.
RPEs signal the difference between expected and received rewards, guiding reinforcement learning by helping the brain adjust behaviours and predictions to maximise future rewards.
EPEs highlight discrepancies between expected and observed outcomes, signalling to the brain to refine its internal models and improve its predictive accuracy.
By integrating these errors into cognitive maps, and using WM gating to focus on the most salient information, the brain enhances its ability to generalise learned routines to entirely new contexts. This adaptability is essential for far transfer, where the skills and knowledge acquired in one setting are applied flexibly and effectively to novel and diverse situations.
Computational Efficiency and Offline Replay
Offline replay, particularly during sleep, is crucial for the consolidation of cognitive maps. This replay process not only strengthens the learned routines but also allows for the integration and optimisation of SR-based predictions without the need for real-time computation. WM gating during wakefulness complements this by ensuring that only the most relevant aspects of these maps are actively maintained and used, enhancing the overall efficiency of the cognitive system. This process enhances the ability to apply learned routines to new tasks by reinforcing the cognitive maps that underpin these routines. Sleep thus plays a critical role in enabling far transfer by ensuring that cognitive maps are robust and flexible enough to support the application of learned skills in novel contexts.
Cognitive Load
Balancing cognitive load throughout the training process is also crucial. Ensuring that the transition from model-free to model-based tasks does not overwhelm the cognitive system but instead builds on a solid foundation of automaticity before introducing flexibility is key to successful far transfer. This balance allows the cognitive system to progressively integrate and apply learned routines to increasingly complex and varied contexts, enhancing the potential for far transfer.
Conclusion: An Integrated Training Approach for Far Transfer
Achieving far transfer in brain training demands a comprehensive approach that integrates the development of automatic, model-free routines with flexible, model-based strategies, all underpinned by cognitive maps. These cognitive maps, consolidated during sleep and modulated by WM gating, are crucial for applying learned routines to new and diverse contexts. By strategically sequencing tasks - from adaptive working memory exercises to strategic mindware training - we can cultivate both efficiency and flexibility in cognitive processes. This approach, grounded in cognitive neuroscience mechanisms like sleep-driven map consolidation and PFC-mediated gating, significantly enhances the potential for far transfer. Through such targeted training programs, we not only boost specific task performance but also promote the adaptability and flexibility essential for cognitive performance in novel and complex real-world environments.
Guidelines for Effective Far Transfer Brain Training
To maximise the effectiveness of a brain training app designed to promote far transfer, the following features can be incorporated that align with the underlying cognitive neuroscience principles. These features not only ensure that users develop automated cognitive skills but also enhance the adaptability and flexibility required for far transfer.
1. Identifying and Reinforcing Shared Cognitive Routines
To design an effective training program, it is important to identify higher-level cognitive routines that are common to both adaptive working memory or attention tasks and mindware tasks. These shared cognitive routines support both model-free and model-based learning processes, providing a foundation for the flexible application of skills across different contexts.
The app should be designed to reinforce these shared cognitive routines across different task types. For instance, tasks that involve executive functioning, such as task-switching and updating information, should be integrated into both working memory and mindware tasks. These shared routines facilitate routine tasks (model-free learning) and provide the cognitive flexibility needed to adapt learned routines to novel situations (model-based learning).
Implementation
Develop tasks that simultaneously engage these shared routines. For example, working memory tasks could be designed to incorporate strategic planning elements, where users must not only remember sequences but also plan their application in complex scenarios. Mindware tasks should similarly draw on attention control and executive functioning, ensuring that these routines are consistently practiced across different contexts. The app should monitor the user's performance on these shared routines and provide feedback that highlights their application across tasks, reinforcing the dual role these routines play in supporting both efficient, automatic behaviours and flexible, adaptive strategies.
2. Adaptive and Incremental Task Progression
To effectively develop cognitive routines and maps that support far transfer, tasks should dynamically adjust in difficulty based on the user's real-time performance while following a structured progression from simple to complex challenges. This ensures that the cognitive load remains challenging yet manageable, allowing for the gradual development of automatic, model-free routines and the flexible application of these routines in novel contexts.
Implementation
Tasks should be adaptive, dynamically adjusting their difficulty levels based on performance metrics, such as the n-back level in working memory exercises. The app should also incorporate a well-defined learning path where each task level builds upon the previous one, gradually increasing in complexity. As users advance, they should face more challenging scenarios that require the integration of previously acquired knowledge, further reinforcing their cognitive maps and enhancing the flexibility of their learned skills.
3. Progressive Complexity in Mindware Tasks
We need to design decision-making and problem-solving mindware challenges that become progressively more complex as the user advances. These tasks should induce the use of model-based strategies, where users must apply forward-looking computations and strategic planning. The cognitive load of these mindware tasks is crucial as it promotes the deployment of automated routines that were developed through adaptive brain training tasks, such as the dual n-back for working memory.
Implementation
Integrate scenarios that involve increasing numbers of variables or introduce more complex decision trees. The app should adapt based on user performance, challenging users to refine and generalise their cognitive strategies across different scenarios. The cognitive maps formed during these tasks will be essential in generalising these strategies across various contexts, ensuring that the learned routines from working memory training are effectively applied in novel and complex problem-solving situations.
4. Real-Time Error Feedback
We can provide users with immediate feedback on their performance, highlighting discrepancies between expected outcomes and actual results. This feedback helps users refine their cognitive models and reinforces the cognitive maps that underpin effective decision-making and problem-solving.
Implementation
Develop a user interface that delivers clear, real-time feedback during and after each task, with summaries of overall performance. This can help users understand and internalise the relationship between their actions and outcomes, supporting far transfer.
5. Total Training Time: 30 Minutes per Day for 20 Days
15 Minutes Dual N-Back Working Memory Training: This time is sufficient to engage and challenge the working memory system without causing excessive cognitive fatigue.
15 Minutes Mindware Training: This period is ideal for engaging higher-order cognitive processes, such as strategic planning and decision-making, without overwhelming the participant.
A 20-day duration strikes a good balance between allowing sufficient time for neuroplastic changes to occur and maintaining participant engagement without leading to burnout. The dual n-back task is intensive and can effectively build automatic, model-free routines within this timeframe. [article]
Far Transfer Principle 2: Optimising Brain Criticality with Mindfulness
Brain Criticality
We hypothesise that the variability in the effectiveness of cognitive training for promoting far transfer -where skills developed in one context are applied to different, more complex tasks -can be partially explained by whether an individual's brain operates in a near-critical state during training. This optimal state enables the brain to dynamically reconfigure itself, efficiently allocating resources to both specialised and integrative tasks. Such dynamic adaptability is crucial for transferring skills and strategies across different contexts.
For example, in a training regime combining dual n-back tasks with Expected Utility Theory (EUT) decision-making, the brain must effectively integrate the model-free routines honed during n-back training with the model-based strategies reinforced during EUT training. When operating near criticality, the brain is better equipped to manage this integration. Segregated networks handle the automatic processing required for n-back tasks, while integrated networks facilitate the flexible application of these routines within the broader strategic framework of EUT.
A brain that is too segregated may become rigid, making it challenging to adapt learned routines to new contexts. Conversely, an overly integrated brain may suffer from inefficiencies due to excessive crosstalk and slower processing times. Thus, maintaining a balance between segregation and integration - a hallmark of brain criticality - is key to successful far transfer.
Brain Modularity Evidence
Brain modularity - the organisation of the brain into distinct, highly connected sub-networks, or modules - plays a critical role in maintaining brain criticality. High modularity allows the brain to process information efficiently within specialised modules (supporting skills and crystallised intelligence) while also facilitating cross-module integration when necessary (supporting strategies and fluid intelligence). This modular structure enables the brain to dynamically switch between segregated and integrated processing modes, a hallmark of brain criticality.
Research by Baniqued and colleagues [article] provides evidence that higher baseline brain modularity predicts greater training-related cognitive gains in tasks involving working memory and reasoning.

Individuals with higher modularity are more likely to experience far transfer cognitive gains from training because their brain's network architecture is optimised for both specialised processing and cross-module communication.
For example, during sustained dual n-back training, the brain consolidates model-free cognitive routines in segregated networks. High brain modularity ensures that these networks operate efficiently, leading to the rapid automation of working memory processes with minimal interference from other cognitive functions.
Combined with an EUT decision-making phase, the brain’s integrated networks (supported by the SR cognitive map system) facilitate the application of these automated routines within a broader, model-based strategic framework. Individuals with higher baseline modularity and criticality experience more effective integration because their brain’s network architecture is optimised for both specialised processing and cross-module communication.
Inducing Brain Criticality with Mindfulness Meditation
Research by Stefan Durschmid and colleagues [article] on electrical currents generated in the brain has shown that mindfulness meditation practices can shift the brain towards this critical state, particularly through high-frequency band brainwave activity (200Hz to 250Hz range). By promoting criticality, mindfulness meditation can potentially optimise brain function, facilitating both the efficiency and flexibility needed during cognitive training. This critical state is hypothesised to enhances the brain's ability to integrate model-free routines with model-based strategies, supporting far transfer across different cognitive tasks, supporting far transfer.
Another recent study [article] found that Open Monitoring Meditation (OMM) significantly enhances brain criticality, as evidenced by an increase in Lempel-Ziv complexity, indicating a richer and more diverse set of neural states. OMM brings the brain closer to the "edge of chaos," a critical state where the brain balances between order and disorder, optimizing cognitive flexibility and processing capacity.
Mindfulness practice is thus hypothesised to optimise their neural networks for far transfer. The findings suggest that mindfulness can be a key strategy in achieving optimal brain-critical states, improving the effectiveness of the training for far transfer.
Situational Awareness
Situational awareness, the ability to perceive and understand the environment in real-time, critically benefits from the brain's operation near criticality. When the brain is in this balanced state, it exhibits a heightened dynamic range, allowing it to be more sensitive to a wide variety of stimuli. This increased sensitivity enables the brain to more easily recognise potential problems, decision points, and learning opportunities. Practices like Open Monitoring Mindfulness (OMM) further enhance situational awareness by promoting brain criticality, helping individuals to maintain a broad, open focus. This kind of mindfulness practice encourages a non-reactive, yet attentive state that optimises the brain’s ability to process and integrate complex, dynamic environmental cues, improving overall situational awareness.
Metacognition
Metacognition, or the awareness and regulation of our own cognitive processes, is significantly enhanced by mindfulness practices, particularly Open Monitoring Mindfulness (OMM). OMM is a reflective state of mind that allows us to observe our thoughts, emotions, and cognitive strategies without immediate judgement or attachment. This reflective capacity is crucial for developing metacognitive skills which benefit the strategic use of mindware, enabling us to monitor and adjust our thinking processes more effectively. This enhanced metacognitive awareness allows for more effective learning, problem-solving, decision-making and strategic planning.
Far Transfer Principle 3: Harnessing Sleep
Research shows that the interplay between sleep, circadian rhythms, and brain criticality is fundamental for optimising cognitive training outcomes and achieving far transfer. Slow Wave Sleep (SWS), in particular, plays a crucial role in the consolidation and refinement of both model-free routines and model-based strategies. During SWS, the brain engages in synaptic homeostasis and neural reorganisation, processes that are essential for extracting gist information, maintaining cognitive flexibility and supporting Successor Representation (SR) encoding. [article]
One of the key mechanisms through which SWS contributes to far transfer is through offline replay. During sleep, especially during SWS, the brain reactivates and reinforces the cognitive maps that have been formed during waking hours. This offline replay strengthens learned routines, allowing for the integration and optimisation of SR-based predictions without the need for real-time computation. As a result, these cognitive maps become more robust and flexible, better supporting the application of learned skills to novel contexts. [article]
Circadian sleep rhythms and slow wave CAP sleep is associated with maintaining the brain at a critical point, facilitating the flexible application of cognitive skills and strategies across diverse and novel contexts. [article 1, article 2]
Research demonstrates that sleep plays a crucial role in consolidating and enhancing training-induced improvements in working memory, particularly when training sessions are closely followed by a period of sleep. [article] This timing allows for the consolidation of learned routines and skills during the subsequent sleep period, leading to more significant improvements in performance.

Far Transfer Principle 4: A Performance Mindset
As explained in my previous article, a performance mindset, which can be significantly influenced by placebo effects, can play an important role in enhancing the effectiveness of brain training for far transfer. When individuals believe that the training they are undertaking will improve their cognitive abilities, this belief triggers a performance mindset characterized by high self-efficacy, a strong focus on achieving cognitive goals, and a positive evaluation of the effort-to-reward ratio. This mindset drives deeper engagement with the training tasks, resulting in more focused and sustained practice, which in turn can lead to measurable improvements in performance. The neurobiological underpinning of this process involves reward-based dopamine pathways, where the anticipation of cognitive gains triggers dopamine release, reinforcing motivation and task engagement. This creates a virtuous cycle, where increased motivation leads to better performance, which further boosts the belief in the effectiveness of the training. Over time, this sustained engagement and enhanced performance can lead to neuroplastic changes that consolidate the skills and strategies being trained, supporting their transfer to broader, real-world contexts. Thus, a performance mindset, even when rooted in placebo-driven expectations, may significantly enhance the potential for far transfer in cognitive training by fostering an environment conducive to deep learning and skill generalisation.
Far Transfer Principle 5: Fitness & High HRV
Physical fitness and a high heart rate variability (HRV) are increasingly recognised as important factors that can enhance cognitive performance and resilience. High HRV, an indicator of a well-regulated autonomic nervous system, reflects the body’s ability to adapt to stress and recover efficiently, which is closely linked to overall cardiovascular and cognitive health. Individuals with high HRV tend to have better cognitive flexibility, emotional regulation, and stress resilience - qualities that are crucial for effective learning and the application of skills across different contexts. Regular physical exercise (aerobic and HIIT), which boosts cardiovascular fitness and increases HRV, also enhances neurogenesis & neuroplasticity, which can benefit training outcomes. This aspect of training will be covered in a follow-up article.
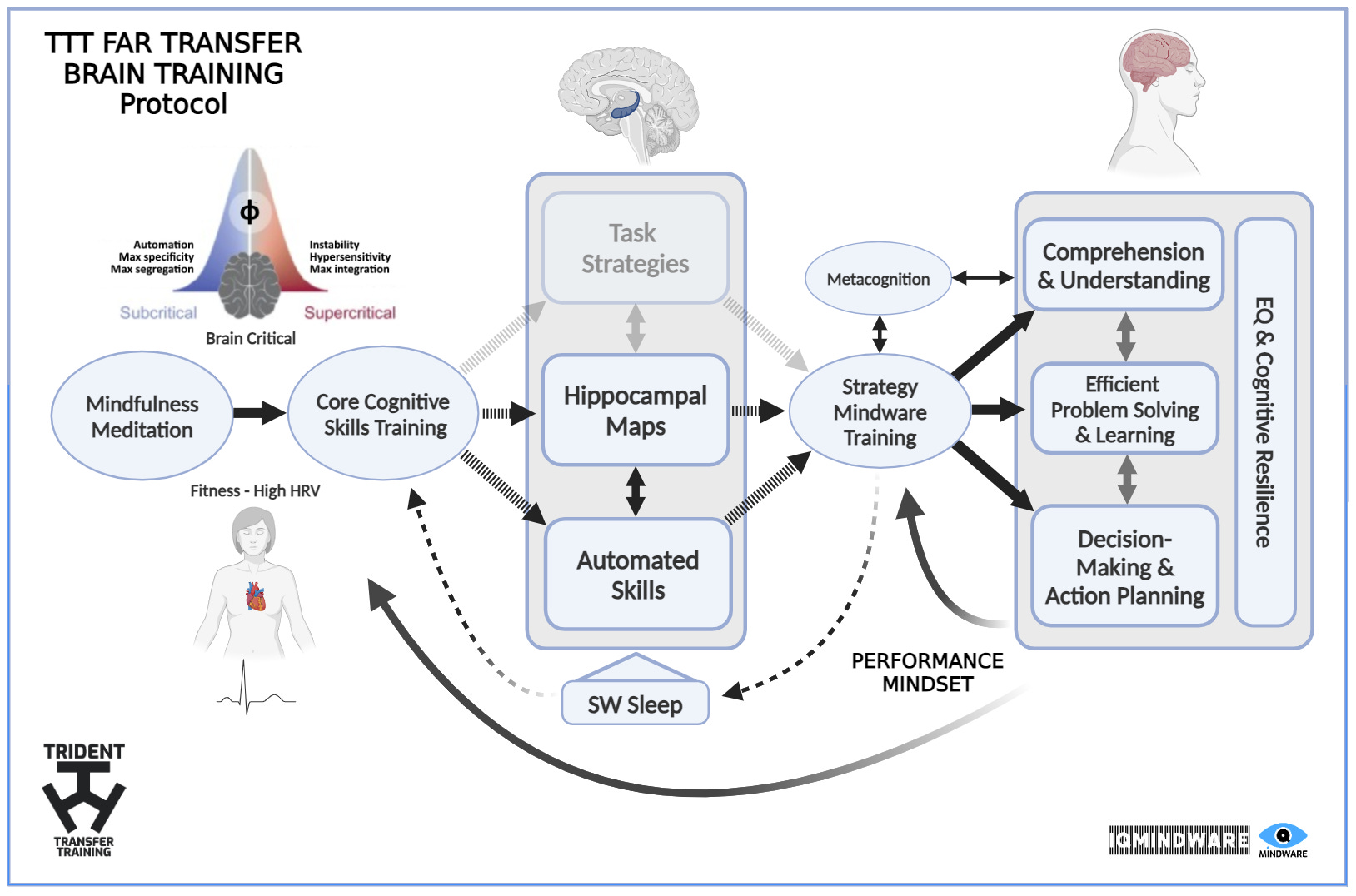
Far Transfer Brain Training Protocol
Based on the above principles we can formulate the basic structure for far transfer brain training as follows:
Mindfulness: In the evening, before beginning the dual n-back training, you practice brief mindfulness meditation session. This helps them achieve a near-critical state, enhancing their brain's capacity for dynamic reconfiguration and neuroplasticity during subsequent cognitive tasks.
Skill Training Phase: During dual n-back training, the brain's segregated networks are consolidated over time, refining model-free routines. These routines, reinforced by prediction error signals, become more efficient and automatic, contributing to the development of crystallised intelligence.
Mindware Training Phase: In the mindware training phase (e.g. EUT based decision-making) the brain's integrated networks coordinate the model-free routines in novel, complex decision-making scenarios. The SR coding in cognitive maps and RPE/EPE signals ensure that the routines developed during n-back training are effectively integrated into model-based strategies, enhancing the fluid intelligence needed for the flexible application of mindware.
Metacognition: Metacognitive practices such as self-explanation and reflective reasoning are always applied while training with and applying the mindware.
Sleep: You ensure that you get restful and regular sleep while you are training to harness the learning and consolidation benefits of slow wave sleep.
6/7/8 Daily Mindware Application: To maintain the brain in a near-critical state during daily cognitive challenges, you practice brief mindfulness exercises prior to applying your mindware for making decisions or solving problems. These exercises help recalibrate criticality, supporting the integration of model-free routines with model-based strategies that underlies the far transfer performance in daily life.
We also ensure that we have the following ‘superstructure’ during our training: a performance mindset and a baseline fitness & high HRV.

Conclusion
The combination of adaptive working memory training for skill automation, mindware training for strategic flexibility, and mindfulness practices to maintain brain criticality, creates an optimal environment for achieving meaningful cognitive gains. Central to this process is the Successor Representation (SR) framework, which, supported by cognitive maps formed in the hippocampus and refined by working memory gating mechanisms in the prefrontal cortex, serves as a crucial bridge between model-free and model-based processes. These cognitive maps, reinforced and consolidated during sleep, provide a structured representation of past experiences that guides future predictions and decisions. Working memory gating ensures that only the most salient information is used, facilitating the flexible application of learned routines to novel and diverse contexts. By integrating these elements into a cohesive training regime, combined with a performance mindset and physical fitness, we can more effectively harness the brain's natural capabilities for learning, adaptability, and far transfer, extending the benefits of cognitive training beyond the specific tasks practiced to a broader range of cognitive domains.
Please comment if you have any thoughts on the thesis developed in this article!
Hi, does the 2g+ n back and recursive n back target both model free and model based learning?