

Brain Training Won’t Transfer Unless It Trains the Right Capacity
An evidence-led protocol for capacity-based fluid-intelligence far transfer - horizontal and vertical

Most brain-training claims fail at the same point.
People improve on the trained task. They get faster. They learn the interface. They discover shortcuts. Their scores rise. But when the surface changes — a new task, a new problem, a real-world decision, a different form of reasoning — the gain often fails to transfer.
That is the central problem of far transfer.
The old promise was simple: train memory, attention or processing speed, and general intelligence will improve. The evidence has never been that simple. Ordinary working-memory training can produce reliable gains on trained and closely related tasks, but broad transfer to fluid intelligence is much harder to demonstrate.
So the question should change.
Not:
Can any brain-training game increase IQ?
But:
What kind of cognitive capacity would have to be trained for far transfer to become plausible?
My current answer is that far transfer depends on training the capacity to construct, hold, transform and re-use relational maps under changing surface conditions.
That is what I mean by capacity-based Gf far transfer.
Gf — fluid intelligence — is not just “working memory span” or “speed”. It is the capacity to solve novel problems by detecting structure, binding variables, inferring relations, testing constraints and adapting when the surface changes. A genuine far-transfer protocol should therefore train not just items or responses, but the deeper relational machinery that makes novel reasoning possible.
The evidence does not yet prove that this can be done at scale. But several recent papers make this mechanism more plausible and more testable.
1. Fluid intelligence is linked to relational map formation
A recent paper by Tenderra and Theves (2025) is important because it connects fluid intelligence to the way people form cognitive maps.
Participants learned object-location associations, while the researchers measured hippocampal representations using fMRI. The key finding was not simply that better memory predicted higher intelligence. Rather, fluid intelligence was related to the degree to which the hippocampus encoded map-like relational structure.
In other words, higher-Gf individuals showed stronger relational integration. Lower-Gf individuals showed representations less consistent with the underlying two-dimensional geometry. The effect was specific to relational processing rather than non-relational item memory.
This is where the hippocampus matters. The hippocampal–entorhinal system is not just a memory store for isolated items. It is increasingly understood as a system for organising relations: where things are, how states connect, what transitions are possible, and how separate experiences can be integrated into a map-like structure. Tenderra and Theves’ finding is important because it suggests that Gf is linked to this relational mapping function, not merely to remembering more information.
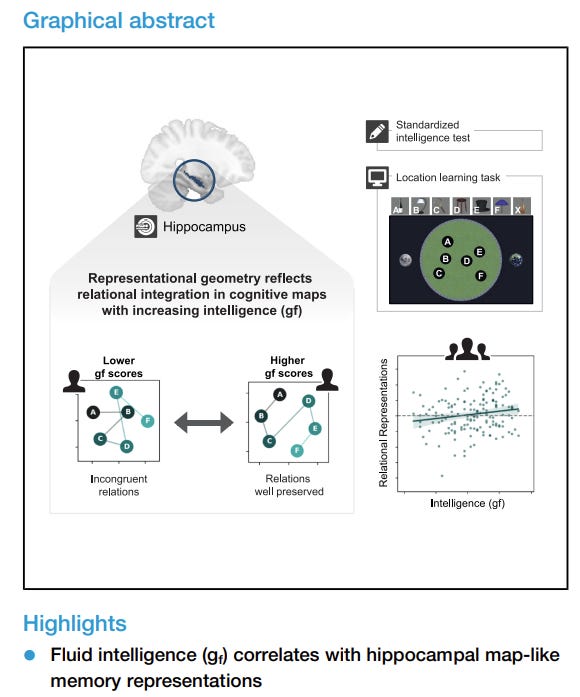
In Trident-G terms, this gives a plausible neural basis for the relational-map layer of intelligence. The hippocampus helps construct the relational possibility space. But using that map for reasoning also requires prefrontal and frontoparietal control systems to select goals, maintain task constraints, test candidate paths and decide which inference should guide action.
All this matters a lot because it moves the intelligence discussion away from the vague idea that “more efficient brain activity” explains Gf. The more precise idea is this:
Fluid intelligence depends partly on how well the brain integrates separate experiences into relational maps that support inference and generalisation.
That is exactly the kind of mechanism a far-transfer training protocol should target.
This also fits evidence that fluid reasoning may be very closely tied to relation processing itself. Jastrzębski, Ociepka and Chuderski (2020) found that a factor based on simple relation-validation tasks was statistically equivalent to a Gf factor measured by standard fluid-reasoning tests. This supports the idea that a Gf protocol should train the ability to validate relations, not just remember items or practise task formats.

A capacity-based Gf protocol should therefore ask:
Can the learner identify the relevant variables?
Can they bind those variables accurately?
Can they track how the relation changes?
Can they infer a hidden structure or future state?
Can they recover the same relation when the surface changes?
This is a very different target from simply remembering more shapes, digits or positions - as you get in standard n-back paradigms.
2. The right target is not item memory, but successor structure
A second line of evidence comes from Successor Representations.
A Successor Representation (SR) is a predictive map. It does not simply encode the current state. It encodes what future states are likely to follow from the current state.
In neural terms, the hippocampal–entorhinal system is the most natural candidate for this kind of predictive map. The hippocampus can represent relational structure, while entorhinal coding provides a metric-like geometry for spaces, paths and abstract dimensions. But an SR is best treated as a distributed computation rather than a thing stored in one place. Once a predictive map is being used for planning, the relevant network likely includes prefrontal cortex, frontoparietal control systems and striatal action-value systems as well.
In ordinary language, the system learns:
If I am here, what becomes reachable next?
That is a powerful idea for intelligence training. Much of reasoning is not just classification. It is solution path evaluation.
When solving a problem, we ask:
What follows from this?
What future state does this move make possible?
Which path is blocked?
Which action preserves the route to the goal?
What hidden structure explains the transitions?
Kahn, Bassett and Daw (2025) provide behavioural evidence that humans learn successor-like predictive representations in graph sequence learning. Their work shows that reaction times can reveal learned expectations over multi-step structure, not merely one-step familiarity.
This is important for a capacity-based training protocol because it suggests a measurable behavioural target: not just whether someone remembers a prior stimulus, but whether they have learned the predictive structure of a state space.
A training task can therefore be designed around the question:
Can this current state still lead to the target?
That is much closer to fluid reasoning than the conventional n-back.
It is also closer to real-world strategic action. In life and work, we rarely need to remember arbitrary items for their own sake. We need to know which move changes the future, and what paths to pursue for likely solutions.
3. Relational working memory is the trainable interface
But there is a bridge missing.
How does a learner get from basic perception to successor-style reasoning?
The answer is relational working memory.
The brain cannot infer a useful transition unless it has first carved the situation into usable variables. Before successor inference, there must be variable abstraction.
A practical training sequence should therefore look like this:
→ feature / variable extraction
→ variable binding
→ relation abstraction
→ successor predictions that help find solutions
→ modality-swaps to test the right relations have been abstacted
→ explicit strategy use
→ delayed re-use
This is why I am interested in perceptual-relational working-memory tasks.
For example, a trial might contain a visual pattern with dimensions such as orientation, spacing and contrast. The learner is not just asked to remember the item. Instead, the task can be structured through four levels:
State tracking
Was this feature the same as before?Binding
Did this feature belong with that feature?Relation tracking
Did the change relation repeat?Successor prediction
Can this state still lead to the target?
The important move is from storage to relation.
A normal working-memory task asks:
Was this the same item?
A relational Gf task asks:
What changed, what stayed invariant, and what follows?
That is the capacity we should be measuring and training.
4. Why the surface must change
Here is where most training programmes go wrong.
They keep the learner in one surface format for too long. The learner improves, but the improvement becomes tied to that format. The system settles into a narrow exploit mode. It has learned “how to do this task”, not “how to recover this relation”. I call this ‘thin automation’.
This is why surface variation is not cosmetic. It is mechanistic.
If the underlying relation is the same, but the wrapper changes, the learner has to re-enter the problem. The old surface-specific strategy no longer works automatically. They must recover the invariant.
This gives us the core horizontal-transfer test:
Can the learner recover the same relational operation under changed surface features or modality?
There is now direct evidence that this kind of near-transfer step matters. Pahor, Seitz and Jaeggi (2022) found that transfer from n-back training to Matrix Reasoning was mediated by improvement on untrained n-back tasks. In other words, the important pattern was not simply “people trained n-back and then scored higher on IQ-like tests”. Rather, farther transfer was linked to whether participants also improved on a different, untrained n-back surface.

That is exactly the kind of result a horizontal-transfer model should take seriously. Before expecting transfer to matrix reasoning or real-world problem solving, the learner should first show that the trained operation survives a changed task wrapper. Near transfer across an untrained surface becomes a gate: if the learner cannot recover the operation when the format changes, there is little reason to expect broader Gf transfer.
The surface features swap should not be random. It should happen after the learner has become locally efficient in the first format. First establish the relation. Then perturb the surface. Then measure the cost and recovery.
This is where learning curves matter.
5. Learning may progress through breakpoints, not one smooth curve
Donner and Hardy (2015) analysed more than 25,000 individual learning curves from cognitive-training tasks. The classic idea is that learning follows a smooth power law: fast gains at first, then diminishing returns.
But individual learning curves were better explained by piecewise power laws. In other words, learning often looks like local improvement within a strategy, followed by a transition to another piece of the curve.
Crucially, later pieces often surpassed earlier ones after a brief performance drop.

That is exactly the kind of pattern we should expect when a learner reorganises their strategy.
For far-transfer training, the key behavioural signature is not endless smooth improvement. It is:
→ local tuning for more efficiency
→ flattening of the learning curve
→ perturbation / change in surface features
→ temporary dip
→ recovery
→ deeper skill and better generalisation (transfer)
The dip matters.
If the surface changes and performance does not change at all, the new wrapper may not be sufficiently different. But if performance collapses completely, the learner may have learned only the surface. The ideal signature is a manageable dip followed by faster recovery.
This would suggest that the learner is not merely repeating a task-specific trick. They are reconstructing the deeper relation.
6. The Ψ-band: between rigid exploitation and runaway exploration
This leads to the central Trident-G idea: effective far-transfer learning requires the learner to remain in a productive zone between exploitation and exploration.
I call this the Ψ (Psi)-band or ‘being in the zone’ where flow is more likely.
Too much exploitation and the learner becomes rigid. They compile a surface-specific strategy and stop searching. Too much exploration and the learner becomes scattered. They keep sampling possibilities without stabilising a useful strategy.
Far transfer requires both:
enough entropy to search beyond the surface
enough constraint to converge on the relevant deeper relation below appearances & lock in a strategy
Zhang and Tang (2025) provide a useful formal model for this. Their computaitonal work on nonequilibrium learning in neural networks argues that learning can be understood through a balance between maximum-entropy exploration and mutual-information constraint. In simpler terms, adaptive learning needs randomness and relevance.
That maps neatly onto the Trident-G training problem.
The learner must remain open enough to reorganise, but constrained enough to find the task-relevant relation. In a cognitive-training protocol, that means the task should not simply get harder in every possible direction. Difficulty must be controlled.
And during training the aim is not to overload the learner. The aim is to keep them in the adaptive band where useful reconfiguration can happen.
7. Automating the right thing
There is a trap here.
Automation is not always good.
If the learner automates the surface, transfer gets worse. If they automate the relational operation, transfer becomes more plausible.
So the aim is not simply to make the user faster. The aim is to increase the mutual information between their responses and the underlying relational abstraction or invariant.
In practical terms, training should make irrelevant surface cues less important and the true relation more available.
The Jastrzębski et al. (2020) result is important here because it suggests that relation validation may be close to the core of Gf. In training terms, the target is therefore not simply faster responding, but faster and more reliable recognition of whether the right relation holds across changing forms.
A learner should gradually move from:
I know what button to press in this task.
to:
I can detect the same relation in a new form.
That is the difference between surface skill and transferable cognitive capacity.
In computational language, the protocol aims to make successor candidates more cheaply available. The learner does not consciously compute every possible inference from scratch. Instead, trained relational maps begin to pre-activate likely paths, blocked paths, lures and possible next states.
The conscious workspace then selects, tests and verbalises the best candidate.
This is where explicit mindware prompts come in:
What changed?
What stayed invariant?
What must be true?
Can this path still reach the goal?
What is tempting but wrong?
What would make this fail?
The ‘meta’ prompts are not the intelligence. They are a control handle. They help the learner select and stabilise a relational operation that lower-level training has made more available.
8. Vertical transfer: from perceptual relation to action strategy
The final step is hierarchy - and what I call ‘vertical transfer’.
Rangarajan and Rao (2026) propose a hierarchical active-inference model using Successor Representations which we looked at earlier. The important idea is that lower-level successor representations can support higher-level abstract states and actions.
That is exactly what a far-transfer protocol needs.
The goal is not to keep the learner inside visual pattern tasks. The goal is to build a ladder:
→ perceptual variable
→ relational transformation
→ successor prediction
→ mindware script
→ real-world action policyA simple perceptual relation might train the operation:
Which variable changed, and what does that change make possible?
A logic puzzle might express the same operation as:
Which move keeps the target reachable?
A real-world mission might express it as:
Which next action preserves the route to the goal?
This is vertical transfer. The same control policy must be reconstructed across layers: perception, working memory, relational inference, explicit prompt and action.
Horizontal transfer asks whether the invariant is locked onto (and survives) with changed task surfaces.
Vertical transfer asks whether the operation becomes usable by higher-level reasoning and action.
A complete Gf training protocol needs both.
9. What this evidence does not prove yet
This framework does not yet prove that IQ Mindware’s training app, or any other training app raises IQ.
But the framework does something important: it makes the far-transfer claim testable.
Instead of saying “brain training works”, it specifies what must survive.
The evidence we would need is not just:
Did the user improve?
but:
Did the user recover the same relation in a new game or real life context?
and:
Did that recovery predict improvement on untrained reasoning, planning or problem-solving tasks?
and:
Did the gain survive after delay - next week, next month?
That is the research programme.
10. The core hypothesis
Here is the hypothesis in one sentence:
Capacity-based Gf far transfer becomes plausible when training increases the learner’s ability to bind variables, track transformations and sample successor relations across changing surfaces, while keeping the learner in a near-critical band between rigid exploitation and scattered exploration.
Or:
Don’t train the task. Train the capacity to recover the relation when the task changes.
That is the difference between practice and far transfer.
11. Why this matters now
We are entering an era where human intelligence is increasingly augmented, challenged and sometimes displaced by artificial intelligence.
In that context, the most valuable human cognitive skill is not memorising more content. It is not playing faster brain games. It is not outsourcing judgement to a machine.
It is the ability to form better models.
To see the structure behind the surface.
To reason and ask what follows.
To recognise when a familiar strategy has become brittle.
To recover the invariant (an underlying relationship) when the world changes.
That is what fluid intelligence does at its best.
A serious far-transfer protocol should be judged by whether it trains that. Not by whether it produces a higher score inside a game. But by whether it helps the learner re-enter the right state, recover the right variables, infer the right relation, test the next move, and carry the structure into a new problem.
That is the future of brain training if it is to become scientifically serious.
Not entertainment with scores.
A measured system for training transferable relational capacity.
References
Donner, Y., & Hardy, J. L. (2015). Piecewise power laws in individual learning curves. Psychonomic Bulletin & Review, 22(5), 1308–1319. https://doi.org/10.3758/s13423-015-0811-x
Jastrzębski, J., Ociepka, M., & Chuderski, A. (2020). Fluid reasoning is equivalent to relation processing. Intelligence, 82, Article 101489. https://doi.org/10.1016/j.intell.2020.101489
Kahn, A. E., Bassett, D. S., & Daw, N. D. (2025). Trial-by-trial learning of successor representations in human behavior. PLOS Computational Biology, 21(11), Article e1013696. https://doi.org/10.1371/journal.pcbi.1013696
Pahor, A., Seitz, A. R., & Jaeggi, S. M. (2022). Near transfer to an unrelated N-back task mediates the effect of N-back working memory training on matrix reasoning. Nature Human Behaviour, 6(9), 1243–1256. https://doi.org/10.1038/s41562-022-01384-w
Rangarajan, P., & Rao, R. P. N. (2026). Hierarchical active inference using successor representations. arXiv. https://doi.org/10.48550/arXiv.2604.15679
Tenderra, R. M., & Theves, S. (2025). Human intelligence relates to neural measures of cognitive map formation. Cell Reports, 44(8), Article 116033. https://doi.org/10.1016/j.celrep.2025.116033
Zhang, X.-Y., & Tang, C. (2025). Heavy-tailed update distributions arise from information-driven self-organization in nonequilibrium learning. Proceedings of the National Academy of Sciences of the United States of America, 122(51), Article e2523012122. https://doi.org/10.1073/pnas.2523012122