

Crystallised Intelligence: Deeper Insights
Why “true Gc” is built by fluid intelligence (Gf), and why 'trust in the process' may degrade our intelligence in corporations

This is a professional cognitive neuroscience grade overview that will give you a solid take on one key aspect of human intelligence - not working memory and reasoning ability, but what we KNOW.
In the classic Gf–Gc theory of intelligence, fluid intelligence (Gf) is your capacity to reason and solve novel problems, while crystallised intelligence (Gc) is the knowledge and skills you accumulate through learning and culture. In the modern psychometric tradition, this distinction sits inside the broader Cattell–Horn–Carroll (CHC) framework, where Gf and Gc are treated as major broad abilities. Crucially, the tradition also contains an investment idea: Gf is “invested” in learning, helping to build Gc over time. (1) (2) (3) (4) This is all well established territory in the field.
Most people stop there and treat Gc as “what you know”. Vocabulary. Facts. Expertise. The stuff you can recall. And of course this accumulates over time. You may have seen a graph like this before.

That definition of Gc is a decent shorthand, but it hides a distinction that matters for education, skill-building, and brain training and importantly for us - for a deeper understanding of general intelligence itself.
What should that blue line in the Gf-Gc graph index? Here’s a clue:
Some learning is thin. Some learning is deep.
Only the ‘deep’ kind deserves the title ‘crystallised intelligence’ (Gc) in any serious sense.
True Gc is portable, transferable knowledge. Knowledge you can access, repurpose, and deploy across contexts and task features. If it does not transfer, it has not really crystallised. Simple stimulus-response procedures or automatic habits can’t be considered ‘intelligent’ - just as rote learning isn’t considered a measure of intelligence.
Thin learning vs deep learning
Thin learning (surface-bound)
Thin learning is improvement that stays locked to cues, task features, and familiar formats. It often shows up as:
“I’m good at this exact interface, but change the format and I struggle.”
“I get fast, but only when the same triggers are present.”
And often:
“I can repeat the routine, but I can’t explain why it works.”
This is often stimulus-led competence: efficient, rapid, and brittle. (10) (11)
Atomic Habits and Standardisation
This is why I have a gripe with the ‘atomic habits’ and corporate mantras such as ‘trust in the process’ and ‘standardisation’ as a general organising principle if it’s pushed too far. This approach can augment speed and efficiency - but often only as thin automation. This can make someone an efficient tool in a given process - but its brittle, narrow and not genuinely smart.
Your ability to generalise and repurpose your knowledge lies at the heart of your intelligence.
Deep learning (relational structure-bound)
Deep learning is when you extract the invariants - underlying patterns and relationships - and compress them into a schema you can re-deploy adaptively elsewhere:
“I can do it in a new task because I recognise the deep pattern.”
“I can explain the rule and use it to generate new moves.”
“I can adapt under novelty because the structure is what I’m using.”
This is relational competence: flexible, generative, and portable. And that is what Trident-G treats as “real Gc”. (5)
Examples of Gc:
Conceptual schema (portable): Bayes / base-rate updating. You learn the invariant relationship posterior ∝ likelihood × prior, so you can reason about medical tests, hiring screens, spam filters, or “is this claim likely true?” without needing the same surface story each time. The wrapper changes, the underlying update rule stays. This is the kind of cross-context transfer the far-transfer literature is trying to pin down. (5)
Procedural schema (portable): the debugging loop. You internalise a general operator chain: state the problem → generate a hypothesis → run a discriminating test → update the model → repeat. Once learned, you can use it for code bugs, research methods, troubleshooting a device, or resolving a misunderstanding in a conversation. Same structure, different domain.
Examples of Thin Automation:
Cue-driven exam tactics. A student learns “when the question says X, do step sequence Y” (keyword spotting + memorised procedure). Performance can look excellent on near-identical questions, but falls apart when the problem is reworded or the surface cues change. That’s near transfer without far transfer. (5)
Habitual UI / routine dependence. You learn a fixed click-path in one software (“export → advanced → tick box → save”), or a rigid work routine triggered by a specific cue. It’s fast and effortless until the interface updates or the context shifts. This maps neatly onto the goal-directed vs stimulus–response habit distinction in the habit literature. (10) (11)
Corporate standardisation / SOP compliance (process stacks low in the hierarchy). In many organisations, competence is built by standardising work into a hierarchy like policy/objectives → process map → procedure/SOP → work instruction → checklist / runbook / script. Staff then learn “the approved steps” for routine cases (great for consistency), but if they never internalise the why (the underlying causal/relational structure), performance can become box-ticking and brittle when the situation deviates from the template. A classic example is a customer support or operations team trained on ticket-category scripts and checklists that work well until a novel edge-case appears, at which point the script doesn’t transfer. (20) (21) (22)
Two kinds of true crystallised intelligence: conceptual and procedural
1) Conceptual Gc (semantic schemas)
This is structured understanding: causal models, principles, categories, situation models.
Thin conceptual learning looks like memorised facts with weak links.
Deep conceptual learning looks like a compressed theory you can apply across domains.
Neuroscience translation: conceptual knowledge is widely treated as distributed, supported by heteromodal systems that integrate meaning beyond any single sensory modality. (6) (7)
2) Procedural Gc (skill schemas)
This is structured doing: methods, routines, operator chains, stable “ways of acting”.
Thin procedural learning looks like cue-triggered habits.
Deep procedural learning looks like hierarchical, goal-structured skills you can run under new task features.
Neuroscience translation: there is a major difference between goal-directed control and habitual cue-driven control, with basal-ganglia circuits strongly implicated in that transition. (10) (11)
The problem with traditional n-back games and cognitive skill training generally
Classic n-back tasks repeatedly rehearse a single, narrow updating routine with highly stable stimulus formats, timing, and response mappings.

With enough repetition, performance improvements can be driven by task-specific routines (efficient heuristics, perceptual familiarity, and a well-rehearsed “task set”) that transfer well to other n-back variants but only weakly to genuinely different cognitive demands. Meta-analytic evidence fits this: transfer is typically largest to untrained n-back tasks, while transfer to broader cognitive control and far-transfer outcomes is very small or inconsistent, and can depend on control-group design. (23) (24) This is exactly the problem tackled by my forthcoming ‘IQ Capacity Coach’ upgrade which draws on computational neuroscience models to promote genuine ‘deep cognitive skill’ extraction from this training.

Where deep Gc, thin habits, and their gates may sit in the brain
There is no single “Gc storage area”. But the thin vs deep distinction maps NICELY onto different systems across the research literature.
A) Deep, portable conceptual schemas (semantic Gc)
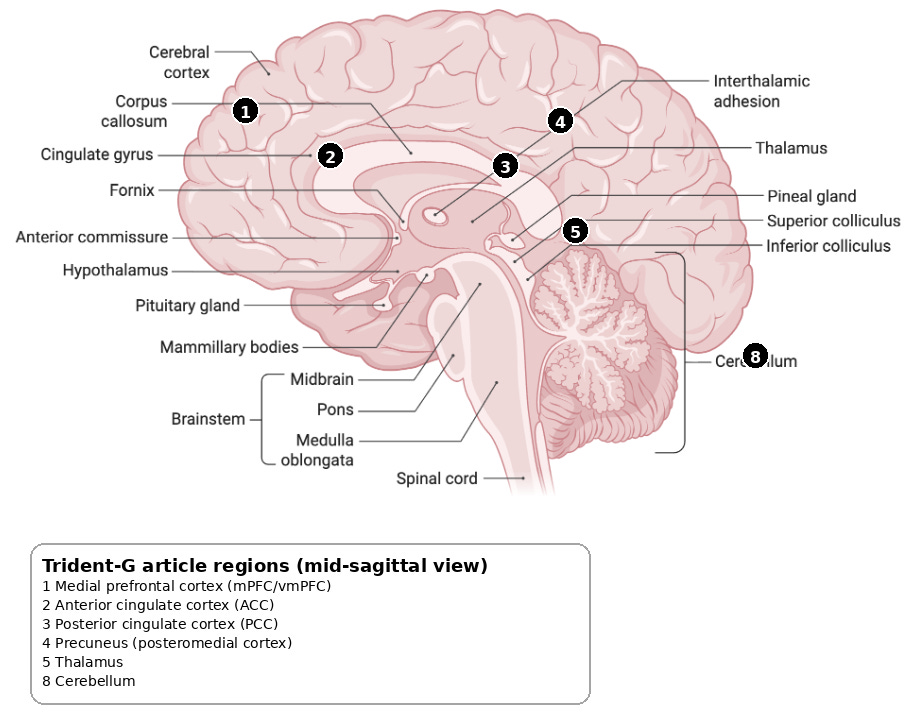
Plausible substrates for portable semantic schemas include:
Anterior temporal lobe (ATL) as a transmodal semantic hub that supports integrated concepts. (6) (7)
Angular gyrus / inferior parietal for heteromodal integration, meaning construction, and schema-like “gist”. (13)
Medial prefrontal cortex (mPFC) in schema-related learning and integration with prior knowledge. (9)
Posterior medial network regions (posterior cingulate, precuneus, etc.) for situation models and memory-guided cognition. (8)
Hippocampus (as an index), together with adjacent parahippocampal cortex: binds episodes and contexts, and helps re-activate distributed schema traces. (8)
A helpful Trident-G translation is: these systems support meaning that can be reached from multiple cues, rather than “one cue, one response”.
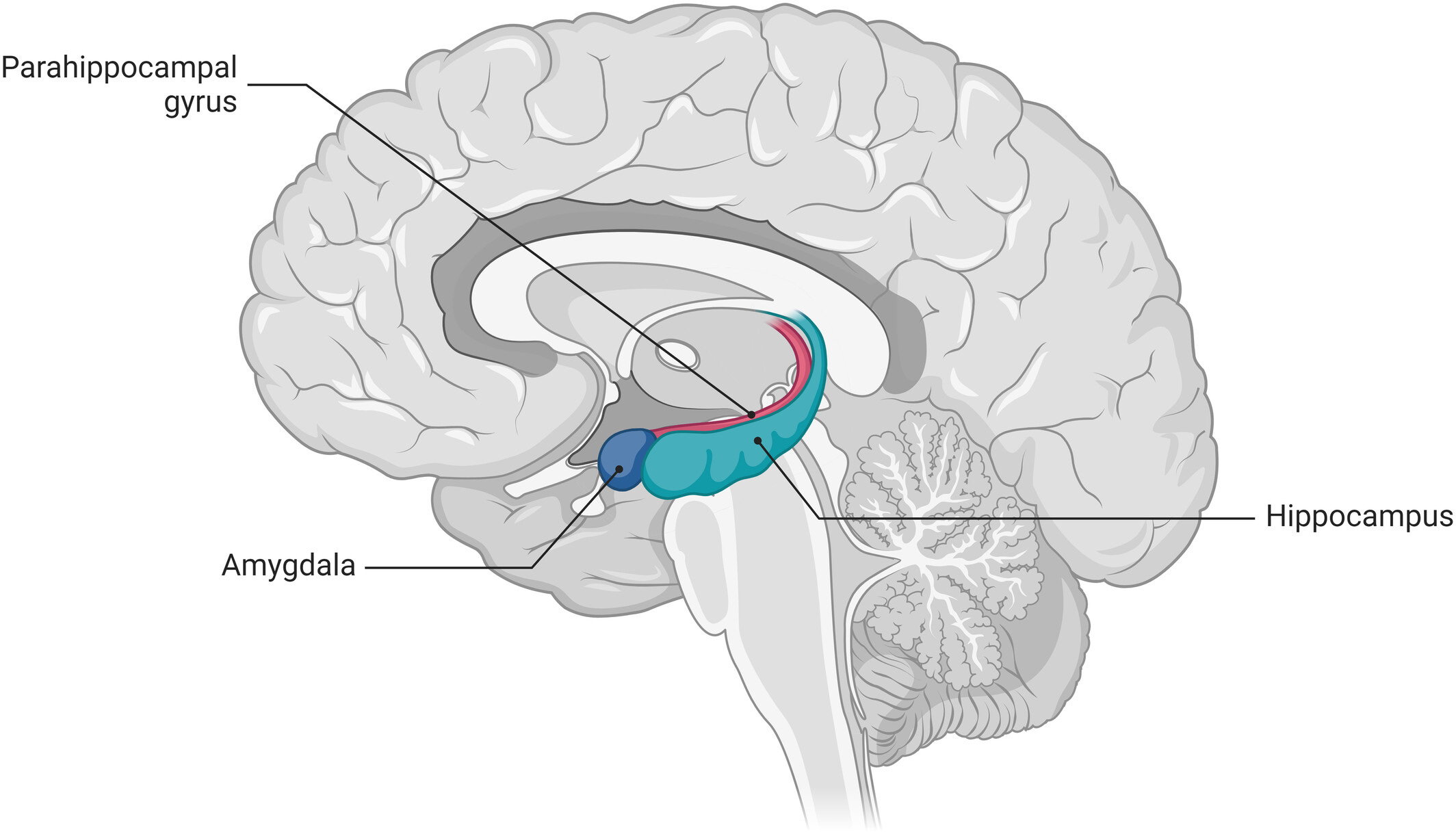
B) Deep, portable procedural schemas (skill Gc)
For portable skills, procedures and methods, plausible substrates include:
Cortico–basal ganglia loops for chunking and proceduralising action sequences into reusable “options”, not just reflexes. (10) (11)
Premotor/SMA style sequencing systems for stable action schemas, meaning how you actually run the routine.
Cerebellum as a predictive internal-model system connected to association networks, plausibly supporting refined, generalisable control policies. (12)
C) Thin learning (cue-locked habits and specific task dependence)
Thin learning is more likely to be dominated by:
Habit-like basal ganglia control where behaviour becomes antecedent-stimulus driven
Task-specific perceptual or sensorimotor pipelines that overfit to the training task
This is efficient and often desirable, but it is exactly where you can get practice gains without far transfer, which is the main problem with most brain-training protocols. (10) (11)
These cue-locked patterns are especially likely when salience is high and control is low, because emotionally charged cues can become fast triggers for a familiar response even when deep structure differs. (16) (17)
D) The “feels” router that makes deep knowledge usable
Even deep schemas fail if you cannot retrieve them under pressure or when they matter.

Transferability of our knowledge depends heavily on selection, switching, and coordination systems that connect with our feelings - such as:
Salience Network (SN)
This large cortical network is anchored by anterior insula / fronto-insular cortex and dorsal ACC, which detects behaviourally relevant change (internal or external) and helps switch between internally focused “default-mode” processing and externally oriented executive control. This switching role has been supported by directed-connectivity evidence and replicated with modelling approaches. In practice, the SN functions as the system’s call-for-control / mode-shift trigger. (28) (29) (30) (31)

Feeling
Importantly, this is where “feeling” enters the picture: anterior insula is strongly implicated in interoceptive awareness and subjective feeling, so deep-schema access is often accompanied by a felt sense of importance, clarity, curiosity, or excitement as your thinking unfolds. (26) (27) By contrast, thin automation can feel comparatively “flat” or purely reactive, because it is driven more by cue-triggered routines than by an actively evolving internal model.

IQ link
Beyond being a “switch”, Salience Network function has been linked to individual differences in fluid reasoning, with SN regions showing positive associations with fluid reasoning measures in large samples. (32)
The Amygdala
This tags salience/value and can amplify what gets prioritised and consolidated. This does not automatically mean thin automation. If the learner has extracted deep structure, amygdala-supported arousal can help stabilise that schema. (15) But generally under high stress/arousal, evidence suggests a shift towards striatal stimulus–response control, accompanied by increased amygdala activity/connectivity to striatum, which is one route to cue-locked responding. (16) (17) This is why toning down amygdala reactivity is often a training goal - such as in IQ Mindware’s emotional n-back game.
Storage is not enough. You need adaptive deployment, and that deployment is partly governed by salience/value systems that determine when to recruit control and what gets reinforced.
(14) (15)
A simple self-test: has your knowledge crystallised?
Pick something you think you “know”, then do one of:
explain it to someone without jargon
apply it in a different domain
use it when the usual cues or context have changed
notice whether you have a felt sense of diverse situations where it might be useful
If it holds up, you are seeing deep structure. That is what Trident-G means by real crystallised intelligence, Gc.
References
(1) Cattell, R. B. (1963). Theory of fluid and crystallized intelligence: A critical experiment. Journal of Educational Psychology, 54(1), 1–22. https://doi.org/10.1037/h0046743
(2) Horn, J. L., & Cattell, R. B. (1966). Refinement and test of the theory of fluid and crystallized general intelligences. Journal of Educational Psychology, 57(5), 253–270. https://doi.org/10.1037/h0023816
(3) McGrew, K. S. (2009). CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research. Intelligence, 37(1), 1–10. https://doi.org/10.1016/j.intell.2008.08.004
(4) Schweizer, K. (2002). A revision of Cattell’s investment theory: Cognitive properties influencing learning. Intelligence, 30(6), 539–555. https://doi.org/10.1016/S1041-6080(02)00062-6
(5) Barnett, S. M., & Ceci, S. J. (2002). When and where do we apply what we learn? A taxonomy for far transfer. Psychological Bulletin, 128(4), 612–637. https://doi.org/10.1037/0033-2909.128.4.612
(6) Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8(12), 976–987. https://doi.org/10.1038/nrn2277
(7) Simmons, W. K., & Martin, A. (2009). The anterior temporal lobes and the functional architecture of semantic memory. Journal of the International Neuropsychological Society, 15(5), 645–649. https://doi.org/10.1017/S1355617709990348
(8) Ranganath, C., & Ritchey, M. (2012). Two cortical systems for memory-guided behaviour. Nature Reviews Neuroscience, 13(10), 713–726. https://doi.org/10.1038/nrn3338
(9) van Kesteren, M. T. R., Ruiter, D. J., Fernández, G., & Henson, R. N. (2012). How schema and novelty augment memory formation. Trends in Neurosciences, 35(4), 211–219. https://doi.org/10.1016/j.tins.2012.02.001
(10) Yin, H. H., & Knowlton, B. J. (2006). The role of the basal ganglia in habit formation. Nature Reviews Neuroscience, 7(6), 464–476. https://doi.org/10.1038/nrn1919
(11) Dolan, R. J., & Dayan, P. (2013). Goals and habits in the brain. Neuron, 80(2), 312–325. https://doi.org/10.1016/j.neuron.2013.09.007
(12) Buckner, R. L. (2013). The cerebellum and cognitive function: 25 years of insight from anatomy and neuroimaging. Neuron, 80(3), 807–815. https://doi.org/10.1016/j.neuron.2013.10.044
(13) Seghier, M. L. (2013). The angular gyrus: Multiple functions and multiple subdivisions. The Neuroscientist, 19(1), 43–61. https://doi.org/10.1177/1073858412440596
(14) Jackson, R. L. (2021). The neural correlates of semantic control revisited. NeuroImage, 224, 117444. https://doi.org/10.1016/j.neuroimage.2020.117444
(15) McGaugh, J. L. (2004). The amygdala modulates the consolidation of memories of emotionally arousing experiences. Annual Review of Neuroscience, 27, 1–28. https://doi.org/10.1146/annurev.neuro.27.070203.144157
(16) Vogel, S., Klumpers, F., Schröder, T. N., et al. (2017). Stress induces a shift towards striatum-dependent stimulus-response learning via the mineralocorticoid receptor. Neuropsychopharmacology, 42, 1262–1271. https://doi.org/10.1038/npp.2016.262
(17) Schwabe, L., & Wolf, O. T. (2011). Stress-induced modulation of instrumental behavior: From goal-directed to habitual control of action. Behavioural Brain Research, 219(2), 321–328. https://doi.org/10.1016/j.bbr.2010.12.038
(20) U.S. Environmental Protection Agency. (2007). Guidance for preparing standard operating procedures (SOPs) (EPA QA/G-6). U.S. EPA.
(21) International Organization for Standardization. (2015). The process approach in ISO 9001:2015. ISO.
(22) Feldman, M. S., & Pentland, B. T. (2003). Reconceptualizing organizational routines as a source of flexibility and change. Administrative Science Quarterly, 48(1), 94–118.
(23) Soveri, A., Antfolk, J., Karlsson, L., Salo, B., & Laine, M. (2017). Working memory training revisited: A multi-level meta-analysis of n-back training studies. Psychonomic Bulletin & Review, 24(4), 1077–1096. https://doi.org/10.3758/s13423-016-1217-0
(24) Melby-Lervåg, M., Redick, T. S., & Hulme, C. (2016). Working memory training does not improve performance on measures of intelligence or other measures of “far transfer”: Evidence from a meta-analytic review. Perspectives on Psychological Science, 11(4), 512–534. https://doi.org/10.1177/1745691616635612
(25) Pessoa, L. (2010). Emotion and cognition and the amygdala: From “what is it?” to “what’s to be done?”. Neuropsychologia, 48(12), 3416–3429. https://doi.org/10.1016/j.neuropsychologia.2010.06.038
(26) Craig, A. D. B. (2009). How do you feel—now? The anterior insula and human awareness. Nature Reviews Neuroscience, 10(1), 59–70. https://doi.org/10.1038/nrn2555
(27) Gruber, M. J., Gelman, B. D., & Ranganath, C. (2014). States of curiosity modulate hippocampus-dependent learning via the dopaminergic circuit. Neuron, 84(2), 486–496. https://doi.org/10.1016/j.neuron.2014.08.060
(28) Seeley, W. W., Menon, V., Schatzberg, A. F., Keller, J., Glover, G. H., Kenna, H., Reiss, A. L., & Greicius, M. D. (2007). Dissociable intrinsic connectivity networks for salience processing and executive control. Journal of Neuroscience, 27(9), 2349–2356. https://doi.org/10.1523/JNEUROSCI.5587-06.2007
(29) Sridharan, D., Levitin, D. J., & Menon, V. (2008). A critical role for the right fronto-insular cortex in switching between central-executive and default-mode networks. Proceedings of the National Academy of Sciences, 105(34), 12569–12574. https://doi.org/10.1073/pnas.0800005105
(30) Goulden, N., Khusnulina, A., Davis, N. J., Bracewell, R. M., Bokde, A. L. W., McNulty, J. P., & Mullins, P. G. (2014). The salience network is responsible for switching between the default mode network and the central executive network: Replication from DCM. NeuroImage, 99, 180–190. https://doi.org/10.1016/j.neuroimage.2014.05.052
(31) Menon, V. (2011). Large-scale brain networks and psychopathology: A unifying triple network model. Trends in Cognitive Sciences, 15(10), 483–506. https://doi.org/10.1016/j.tics.2011.08.003
(32) Yuan, Z., Qin, W., Wang, D., Jiang, T., Zhang, Y., & Yu, C. (2012). The salience network contributes to an individual's fluid reasoning capacity. Behavioural Brain Research, 229(2), 384–390. https://doi.org/10.1016/j.bbr.2012.01.037