

Deep Learning: Speed, Slope and Shape
Why the right life-path brings steep gains, dips and deeper restructuring for growth

We often think of learning as being about one question: am I improving?
But this can be the wrong take on your efforts.
Often the better question is: what kind of curve am I on?
Because not all improvement curves are equal - Some are fertile/productive. Some are shallow. Some give you a burst of rapid gains, then flatten, then force a deeper restructuring. Others never really “take off” at all. They just let you become more polished, more efficient, and more trapped inside something too narrow to change your life.
The speed matters. The slope matters. The shape matters.
And if you do not understand that, you can easily give up at exactly the wrong moment — or persist for years on exactly the wrong surface.
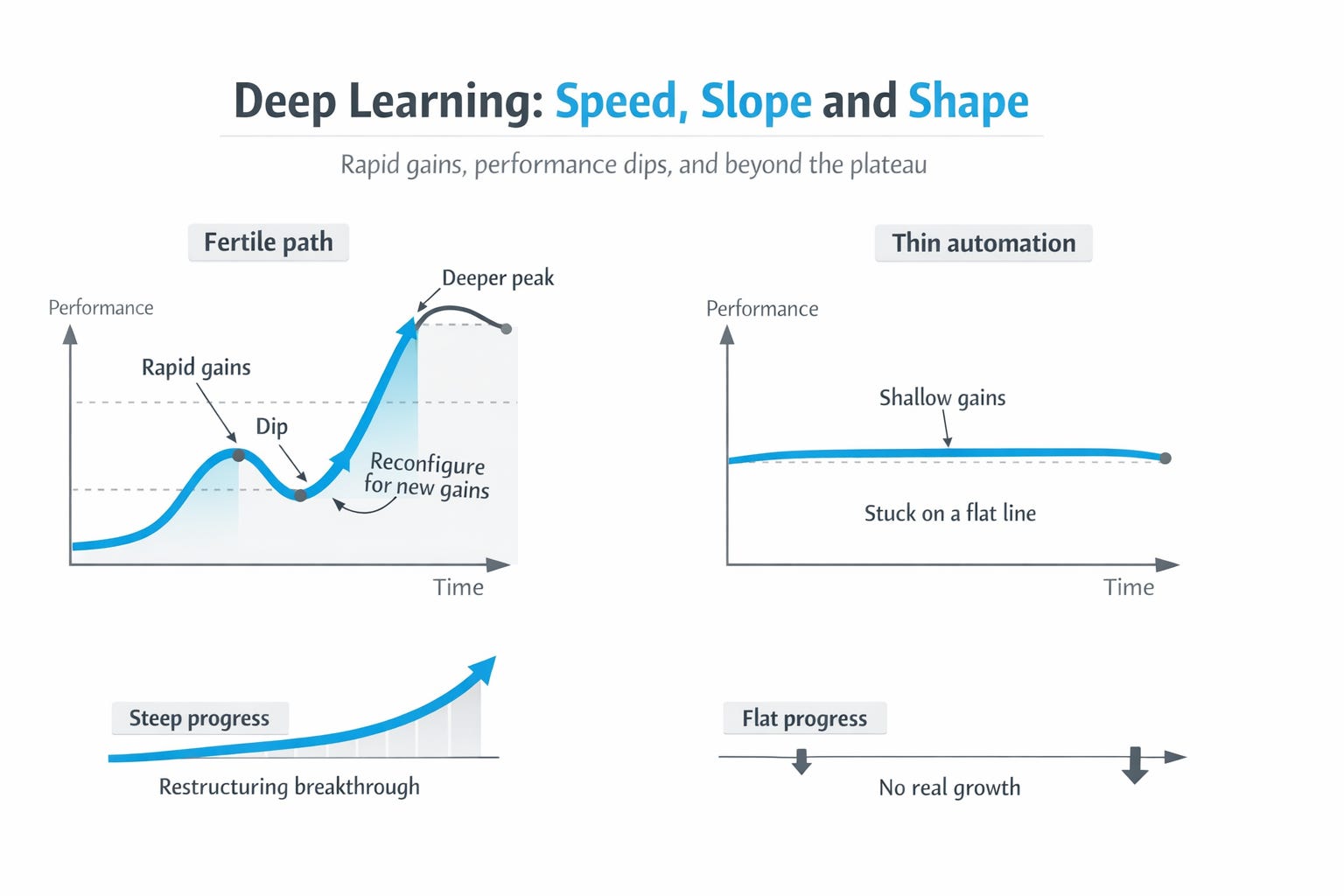
The classic power-law view of learning says that gains often come quickly at first and then slow down. Donner and Hardy sharpened that picture by showing that individual learning curves are often better described not as one smooth power law, but as piecewise curves: periods of rapid local improvement within a strategy, punctuated by strategy shifts, often with a brief performance drop at the transition before climbing again from a higher base. That is the key: fast descent, flattening, awkward restructuring, then a new climb. (1)
That gives us two very different life scenarios if we understand that learning curves operate across multiple scales from minutes to months.
Scenario one: the good bowl
You change something important.
You leave a job. You adopt a new AI workflow. You rethink your business model. You stop trying to solve a problem with the old mental machinery and start using a better representation.
Then something compelling happens.
You make rapid progress. Dopamine is in full flow!
The new configuration gives you a steep early slope. Things click. Gains come quickly. Your effort suddenly converts into visible results. You are not just grinding harder. You are descending a better bowl.
This is what a fruitful local basin feels like. Once you have the right representation, the right tools, or the right operator, exploitation starts paying off fast. That is entirely consistent with the learning-curve literature and with James March’s broader argument about exploration and exploitation: exploitation refines existing certainties more rapidly than exploration discovers new ones. (2)
But good bowls do not go on forever!
The early slope flattens. The easy gains are harvested. The same strategy that felt exhilarating now starts to stall. The thing that looked like take-off starts to look like a plateau. Think of a foraging animal in a berry patch: at first, food is everywhere. A few quick movements bring easy reward. But soon the visible fruit has been picked clean. The animal can keep searching the same bush for smaller and harder-to-reach berries, but the rate of return has changed. What felt abundant now yields only scraps.
This is the pivot point where many people make the wrong call.
They think the stall means the whole strategy has failed.

Often it means something else: you have reached the bottom of the current bowl.
At that point, there are only two real options.
One is to give up and retreat to the old configuration.
The other is to recognise that the first wave of gains was real, bank what it taught you, and tolerate a period of temporary disorganisation while you reconfigure for a deeper descent.
This is where the dip appears.
And this is where people often misread the signal.
The drop in performance after a transition is not necessarily evidence that the new direction is wrong. Donner and Hardy found that later curve segments typically outperformed earlier ones after a brief drop at the transition point. In other words, the system often gets worse before it gets better because one strategy is being destabilised before a better one becomes fluent. (3)
There is converging support for this broader picture. In motor learning, Smith, Ghazizadeh, and Shadmehr found evidence for at least two interacting learning processes with different rates and retention properties, even on a timescale of minutes. In changing environments, learning should jump more strongly when surprising outcomes signal a real shift rather than mere noise. And in rule learning, behavioural transitions can be accompanied by abrupt neural state transitions rather than smooth drift. Learning, in other words, is often multi-timescale, sometimes punctuated, and not reducible to one uniform process of gradual improvement. (4)
Scenario two: the wrong hill
Now consider the opposite case.
You are working hard. You are becoming more efficient. You are learning routines, polishing technique, smoothing the workflow, reducing friction. On paper, this still looks like improvement.
But something is missing.
There is no real take-off. Maybe in a business there is no scaling. In publication work, there is no breakthrough publication-impact-reputation cycle.
There is no steep early slope that suggests you have found a genuinely fertile basin. There is no strong sense that a better representation, better operator, or better strategic frame has suddenly opened a new descent. Instead, the gains are thin, local, and quickly absorbed by the same narrow structure you were already trapped inside.
You are not descending a good bowl. You are just becoming more efficient on the wrong hill.
This is what I have calledl thin automation.
Plug: Thin automation the problem of most brain training, and what IQMindware’s mission aims to counter.
Thin automation happens when learning is real, but too shallow to be transformative. You get better at the ‘wrapper’ - the surface - not at the deeper structure. You become faster at the workflow, smoother in the meeting, more polished in the current job, more competent inside the local game — but your adaptive range does not really expand. The gains do not travel. They do not open a wider repertoire. They do not produce the kind of portable competence that changes what you can do across contexts so you feel like you are genuinely progressing and growing.
This is why some careers, roles, and routines feel so strangely deadening even while they reward competence. They let you optimise, but only locally. They offer enough reinforcement to keep you going, but not enough structural depth to trigger repeated descent in deeper learning bowls. You get better, but not broader. Sharper, but not deeper. More efficient, but not more free. You’re not evolving.

In Trident-G terms, this is the difference between growth and context-bound success. A genuinely productive path enlarges viable range and deeper, portable competence. A shallow path mainly rewards local performance inside one setup. The system may still learn, but what it learns does not survive much variation. It does not travel well across contexts, stakes, or domains.
This matters because the subjective experience can be confusing. Thin automation does not always feel bad in the short term. Sometimes it feels orderly, competent, and safe. Sometimes it even brings status or praise. But over time, something stagnates. There is little real reconfiguration, little widening, and little evidence that the learning is becoming structurally richer. You are moving, but not really going anywhere.
That is the deeper danger: not the dramatic failure of the wrong strategy, but the quiet success of a strategy too shallow to build a life on.
Caution: The fluency trap
There is one important complication to the picture above.
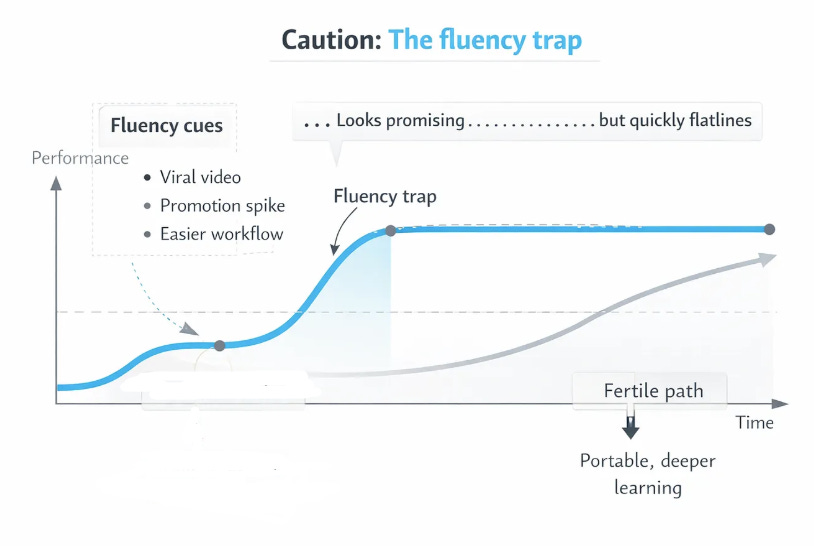
Not every early surge means you have found a good bowl.
Sometimes what feels like rapid progress is only fluency: the ease, smoothness, or social reward of a configuration that looks promising but is not actually producing deep learning or portable growth. A viral video can feel like validation. A promotion spike can feel like destiny. A new workflow can feel brilliantly efficient. But some of these gains are local, performative, or surface-bound. They create the impression of “finally being on the right path” while in fact flattening almost immediately.
The learning literature is very clear on this point. People are often misled by fluency cues. In studies of lecture fluency, students rated a more fluent instructor as better and predicted more learning, even though actual learning did not improve (5). More broadly, metacognitive work on the illusion of competence shows that ease, familiarity, and coherence can be mistaken for genuine mastery. What feels smooth is not always what transfers. (6)
That is why rate alone is not enough. A steep early slope is encouraging, but it is not self-validating. The real test is whether the gains travel. Do they survive a change of context? Do they hold up under pressure? Do they still work when the surface context changes? Do they deepen your adaptive range, or merely make you more polished inside one narrow setup?
In summary, we can be misled in mistaking surface traction for structural growth. We optimise a surface because it gives quick local rewards, when in fact it is only a mud-bank: easy to slide into, hard to build from, and fundamentally too shallow to carry real expansion.
Sources
Carpenter, S. K., Wilford, M. M., Kornell, N., & Mullaney, K. M. (2013). Appearances can be deceiving: Instructor fluency increases perceptions of learning without increasing actual learning. Psychonomic Bulletin & Review, 20(6), 1350–1356. https://doi.org/10.3758/s13423-013-0442-z.
Donner, Y., & Hardy, J. L. (2015). Piecewise power laws in individual learning curves. Psychonomic Bulletin & Review, 22(5), 1308–1319. https://doi.org/10.3758/s13423-015-0811-x (Springer)
Durstewitz, D., Vittoz, N. M., Floresco, S. B., & Seamans, J. K. (2010). Abrupt transitions between prefrontal neural ensemble states accompany behavioral transitions during rule learning. Neuron, 66(3), 438–448. https://doi.org/10.1016/j.neuron.2010.03.029 (PubMed)
Koriat, A., & Bjork, R. A. (2005). Illusions of competence in monitoring one’s knowledge during study. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(2), 187–194. https://doi.org/10.1037/0278-7393.31.2.187
March, J. G. (1991). Exploration and exploitation in organizational learning. Organization Science, 2(1), 71–87. https://doi.org/10.1287/orsc.2.1.71 (pubsonline.informs.org)
Nassar, M. R., Wilson, R. C., Heasly, B., & Gold, J. I. (2010). An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environment. Journal of Neuroscience, 30(37), 12366–12378. https://doi.org/10.1523/JNEUROSCI.0822-10.2010 (PMC)
Smith, M. A., Ghazizadeh, A., & Shadmehr, R. (2006). Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biology, 4(6), e179. https://doi.org/10.1371/journal.pbio.0040179 (PubMed)
Zhang, X.-Y., & Tang, C. (2025). Heavy-tailed update distributions arise from information-driven self-organization in nonequilibrium learning. Proceedings of the National Academy of Sciences of the United States of America, 122(51), e2523012122. https://doi.org/10.1073/pnas.2523012122 (PMC)