

The g Loop: How Intelligence Learns, Adapts and Decides - Part 2
Learn Better: How Your Mind Updates Its Beliefs, Adapts to Surprises, and Navigates an Increasingly Chaotic World

In Part 1 of this article series, I used the g Loop to explore how our brains handle prediction errors (δ), adjust their learning rate (α), and make Bayesian-style decisions in an ever-changing world. We saw that tuning our learning rate is crucial for balancing rapid adaptation with stability, determining when to rely on old knowledge and existing patterns and when to revise our mental models and explore new ground.
The g Loop
Here is that that deep code for intelligence - the g Loop - again; this time with a useful key:
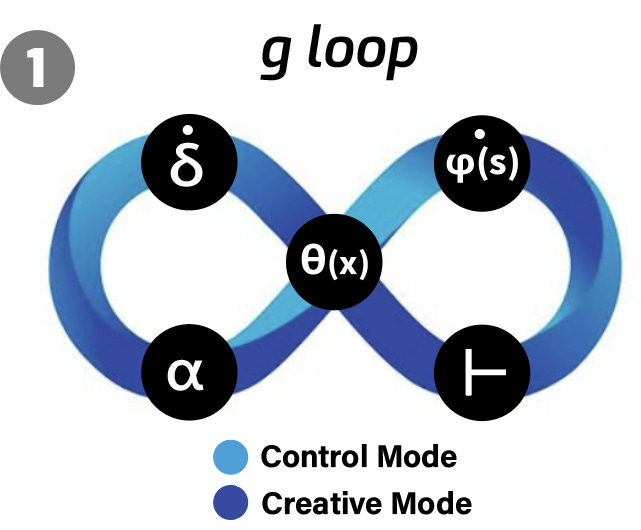
δ (delta): Measures how far off your expectations were from reality (the “surprise” or prediction error signal).
Neurobiology: Driven by phasic dopamine bursts (midbrain VTA/SNc projections to striatum and prefrontal cortex) that rapidly signal sensory and reward mismatches.
α (alpha): Dynamically adjusts how strongly new information (δ) updates your internal model (your “learning rate”).
Neurobiology: Influenced by tonic dopamine levels (along with noradrenergic and cholinergic modulation) that set the baseline readiness for learning and balance exploration versus exploitation.
θ(x) (theta): Sets the decision boundary between exploring new possibilities or sticking to what you know and moves you through a problem space of options.
Neurobiology: Controlled by anterior cingulate cortex (ACC) & dorsomedial prefrontal cortex (dmPFC), regulating exploration-exploitation balance with serotonergic influence.
ϕ(s) (phi(s)): Represents your internal mental model or skill set, refined by prediction errors.
Neurobiology: Stored and updated through hippocampal networks (spatial & conceptual maps) and prefrontal-striatal loops for cognitive flexibility.
⊢ (turnstile): The inferences you make in working memory that draw from updated knowledge with context and existing knowledge.
Neurobiology: Mediated by dorsolateral prefrontal cortex (DLPFC) & parietal cortex, integrating working memory, rule application, and logical reasoning via cholinergic & dopaminergic interactions.
Creative Mode (Light Blue Loop Segment):
Explores new ideas and strategies, and novel connections under high α,Driven by dopamine D1‐mediated synaptic potentiation (LTP).
Control Mode (Dark Blue Loop Segment):
Exploits, consolidates and prunes existing knowledge under low α,Driven by dopamine D2‐mediated synaptic depression (LTD).
Mental Model Cognitive Biases
We may have a tendency to over‐react to new or uncertain information - raising our learning rate α too high - and constantly over-react or abandon what we know in favour of the latest data point. This can lead to “jumping to conclusions,” where we treat every small fluctuation as a major signal to pivot. On the other hand, we may display what psychologists call conservatism bias - a tendency to update our beliefs too slowly or reluctantly, clinging to established mindsets even when the evidence calls for change.
In both cases, the dynamic learning rate is effectively miscalibrated, skewing our ability to adapt in proportion to real‐world demands.
These biases highlight why it is so important to recognise how our internal ‘volume knob’ for learning might be set incorrectly. If we find ourselves flip‐flopping on decisions every time a small surprise arises, we may need to turn that knob down. Conversely, if we suspect we are ignoring genuine red flags or new opportunities, it could be time to turn it up. In practice, self‐awareness about where we sit on this spectrum can help us achieve a better balance between rapid exploration and the reliable exploitation of our existing knowledge.
Dynamic Learning Rate in Recursive Skill Learning
Now we are going to zoom in on the skill-learning side of things, illustrating how the same mechanism that helps us make consistently good decisions (and avoid overreacting or be too overcommitted to our current understanding) also drives our progression from fumbling beginner to competent expert.
We’ll then tie everything together to show why the g Loop can serve as a grand strategy for learning, problem-solving and personal growth.
What Is Recursive Skill Learning?
Recursive skill learning is the process of gradually refining a skill through repeated attempts - often a cycle of trial and error, then adjust, then try again. Each practice run, whether you are learning to get to a 3 back in the dual n-back (www.iqmindware.com), do a throw, or memorise a chord progression on guitar, generates a new wave of prediction errors (δ). Those errors then update your internal model of the skill - represented by ϕ(s) in the g Loop - so that each subsequent attempt starts on a slightly better footing than the last.

Crucially, this cycle is recursive because each improvement in your internal model sets the stage for the next iteration of practice. Over time, you move from big changes (large α) to subtle fine-tuning (small α), reflecting the transition from creative exploration (novice phase) to stable exploitation (expert phase).
Extending to the Power Curve and Strategy Shifts
Empirical studies often show a power law of practice - an overall curve where performance improves rapidly at first, then decelerates over time. Check out the data from the Lumosity study below. This insightful Donner & Hardy (2015) data on cognitive training tasks (including a 1-back and 2‐back working memory training task) reveals a smooth, continuous improvement on average that fits this classic power‐curve shape. But if you look at individual participants (4 shown below in each row), the story is more interesting. You see discrete jumps at certain points in training, which coincide with adopting entirely new strategies. If you have tried the dual n-back or other brain training games, you should have a sense of what this means - but it applies to most skill learning.
The pie charts from that study in the figure below capture how much time is spent in each strategy, showing how the same overall task can evoke multiple strategic phases, each with its own learning curve for each individual,
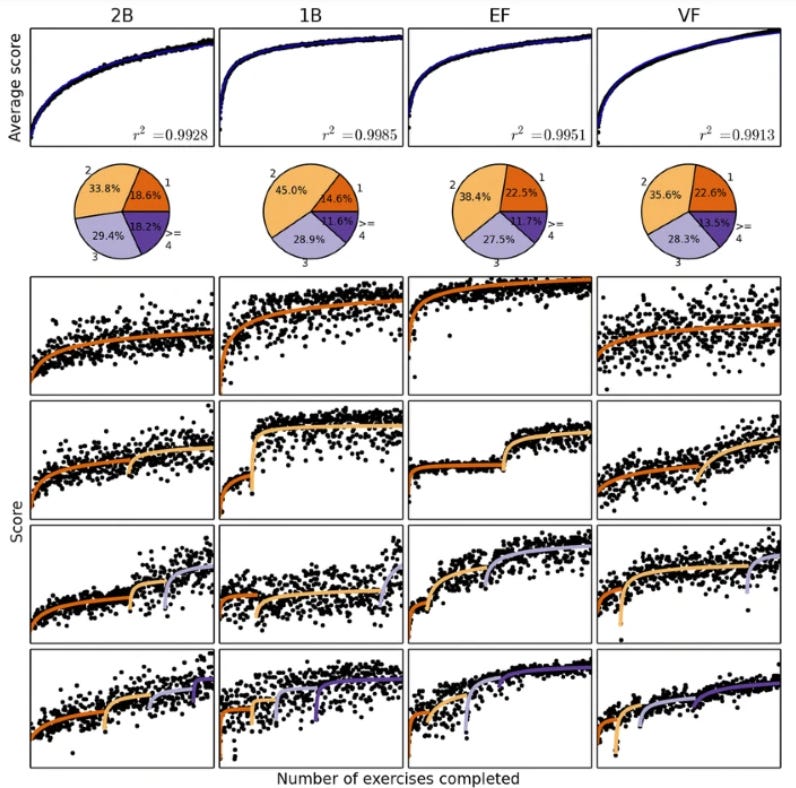
Disruptive Transition: Shifting Between Established and New Cognitive Maps (ϕ(s))
How to explain this? Well each strategy shift corresponds to a fundamental change in the internal model of the skill - ϕ(s) - top right in the g Loop. When we switch strategies, we reset parts of our cognitive map - with new rules or tactics (like chunking techniques) that reorganise how we process information.
Why does performance drop?
The new cognitive model is still untested and exploratory - it lacks the fluency of the previous strategy that has been at work.
Prediction errors (δ) increase momentarily because expectations (predictions) built on the old model do not align with the new approach.
The decision threshold (θ(x)) is temporarily lower, increasing exploration with new tactics, and this also makes actions more inconsistent.
This temporary drop in performance (with more ups and downs of performance reflects the cost of engaging in a more exploratory Creative Mode (high α, broad update with reframing of ϕ(s), the mental model). You struggle initially as your brain reorganises the internal structure of the task, adapting new pathways and suppressing old, no-longer-relevant ones.
2. Power Law Recovery: Fine-Tuning and Optimisation Within the New Strategy
Once the new strategy has been adopted, learning follows a power law because:
As errors (δ) shrink, α decreases, shifting from exploration (Creative Mode) to exploitation (Control Mode).
The decision threshold (θ(x)) increases, meaning your brain stabilises the execution of the strategy and stops adjusting constantly.
This results in smooth, gradual performance improvements within that strategy, until asymptoting at a new plateau - a limit determined by how optimised that strategy is. If the plateau is still suboptimal, another strategy shift might occur, repeating the cycle.
Keep this in mind as you do your cognitive training to augment your IQ Key Takeaways for the g Loop
The drop in performance at a strategy shift happens because your brain must momentarily abandon a well-practiced model (ϕ(s)) and engage in high-α exploration. This increases δ and reduces performance initially.
Recovery follows a power law as α decreases and the strategy is refined within Control Mode.
The overall learning trajectory is piecewise because each new strategy comes with its own learning curve, rather than being a gradual, continuous refinement.
This adaptive switching mechanism ensures that learners can escape local optima, discovering higher-level strategies that ultimately lead to superior performance.
g Loop Tie-In
The g loop model tells us that every time you practise a skill, two key things happen:
1. You generate a prediction error (δ).
If the discrepancy between your intended performance and actual performance is large (e.g. you keep hitting the wrong piano notes), your brain treats this as a significant mismatch. It responds by raising α (the dynamic learning rate), pushing you into Creative Mode - where you explore new strategies, forge new neural connections, and attempt different approaches.
If errors become small and consistent, α drops. Your brain assumes the skill is stabilising and shifts into Control Mode, which consolidates neural pathways and prunes ineffective connections, exploiting the strategy you have.
2. You update your internal model of the skill (ϕ(s)).
During Creative Mode, the system broadens your cognitive map of the skill - experimenting with new strategies such as alternative finger placements, hand positioning, or rhythm adjustments.
During Control Mode, it locks in the most effective patterns and automatises them, shifting from conscious effort to fluent, near-automatic execution.
Because each attempt feeds back into the next, the learning process is not a smooth curve. While early practice involves continuous improvement within a strategy, you will occasionally experience temporary dips in performance when you switch strategies. Each strategy shift resets α, leading to an initial decline before steady improvements emerge, forming a staircase-like progression within the overall power law of learning.
Everyday Example: Learning a Musical Instrument
If you have ever tried to learn a new instrument (fairly recently), you may be familiar with all this…but the same process applies to all complex skills we may want to learn, including cognitive skills such as in my Trident G programs:
Early Days (High α, Creative Mode).
You are all over the place, making big, obvious mistakes. Your dynamic learning rate is high because each error is instructive - the g loop flags them as important. You keep adjusting your posture, finger positions, and sense of rhythm. It can be frustrating, but it is also when you make the fastest progress. (Initial part of the power curve.)Intermediate Phase (Moderate α).
As you adjust to the new strategy, prediction errors decrease, and α stabilises. You start hitting more correct notes than wrong ones. Your skill feels smoother, though not yet effortless. Your performance then starts to plateau as you approach the limits of your current strategy. (Power curve flattens.)Strategy Shifts (Temporary Drop in Performance).
After some success, you realise your current approach is limited (e.g. your right-hand technique lacks efficiency), so you adopt a new strategy. This initially worsens performance as your brain attempts to integrate an unfamiliar approach into ϕ(s). Your prediction error (δ) rises again, temporarily pushing α up as your brain searches for a new equilibrium.Expert Phase (Low α, Control Mode, Transition from Gf to Gc).
Repeated successes reduce errors to a minimum. You rarely play a note out of tune; your motor memory is well-ingrained. Now, your brain invests fewer resources in attention control & error-monitoring, and the skill becomes crystallised - an automated, efficient routine. However, if you encounter an unexpected challenge (e.g. playing in a new style or tempo), prediction errors (δ) spike again, prompting a temporary boost in α to allow for readjustment.
Transitioning from Gf to Gc: The Automation of Optimal Strategies
In this process, fluid intelligence (Gf) - which relies on working memory-intensive problem-solving and flexible reasoning - drives initial strategy formation. Working memory is capacity limited. When learning a new skill, especially one involving complex rule application (such as musical phrasing, finger coordination, or coding logic), attention & working memory capacity becomes a bottleneck. This is why we train these cognitive abilities ot increase intelligence using games like the DNB.
As your strategies become more refined and efficient, they shift from Gf to crystallised intelligence (Gc), where they no longer require conscious working memory effort. Cognitive load reduces. This transition allows the brain to offload optimised patterns to long-term procedural knowledge, freeing up cognitive resources for new challenges or multi-tasking.
In terms of what is going on in the brain In terms of what is going on in the brain, this transition from Gf to Gc involves a shift in neural processing from prefrontal working memory circuits to more distributed, automated networks in the basal ganglia, motor cortex, posterior cortical areas and cerebellum.
Sleep also plays a role (see diagram below). In the early practice phase (high α), broad neural engagement in the prefrontal cortex, motor cortex, and basal ganglia drives exploratory trial‐and‐error. During sleep, replay mechanisms in the hippocampus and motor cortex selectively strengthen useful connections while pruning away the rest, refining the internal model (ϕ(s)) and aligning with the g loop’s rescaling process. Finally, once a skill is mastered (low α), the transition from Gf to Gc is evident: prefrontal demand declines and more efficient, subcortical motor networks take over, resulting in a smoother, less cognitively taxing performance.
 Early Practice: Many neurons activate to perform the skill, even ones that aren’t needed. 2) Sleep: The key cells needed for skill are reinforced. 3) Skill Mastered: Only vital neurons fire.")
So the final stage of expertise is not just “better” performance, but performance that is more automatic, efficient, and cognitively effortless, leveraging Gc instead of Gf. However, any major new challenge or unfamiliar variation (e.g., improvising in a new style) will once again increase working memory demands, forcing a temporary return to Gf-driven active learning - a key feature of the g loop's adaptive intelligence cycle.
Bringing It All Together: Strategic Thinking in Action
We have now looked at how the g Loop explains both fast decision-making (via Bayesian reasoning) and gradual skill mastery (via recursive learning). In practice, these are two sides of the same coin: you are always updating your beliefs or refining your skills based on the size and reliability of prediction errors.
Unified Perspective
From what you do (skill learning) to how you think (Bayesian updates), the dynamic learning rate is the engine that drives:
Rapid Adaptation when the world or your task is unpredictable. This is working memory and fluid intelligence demanding - and limited bandwidth.
Steady Consolidation when you have got a handle on things and want to maintain and automatate consistent performance, freeing up bandwidth and reducing cognitive load.
We can see these principles in the underlying neurobiology: phasic dopamine signals for immediate reward or error updates, tonic dopamine for baseline exploration vs. exploitation settings, and precision weighting (π_e, π_r) that ensures your system learns more from reliable data than from random noise.
Take Homes For Your Own Cognitive Training
By understanding how your dynamic learning rate works, you can:
Enhance Personal Development:
Recognise that initial struggles are part of high-α learning. Embrace them - this is where the big leaps in skill happen.
Notice when you keep making the same mistake - maybe your α is too low (you are ignoring valuable error signals), or perhaps you need more practice in Creative Mode to find a better approach. You may be subject to conservatism bias.
Improve Learning Strategies:
Pace your practice. Short bursts of focused exploration may be more benefitical than marathon sessions that ignore your natural learning rate cycles.
Use feedback effectively. For instance, record yourself performing a task and analyse the biggest discrepancies - this harnesses large δ to encourage real updates.
Make More Adaptive Decisions:
In uncertain situations (a volatile environment), accept that you need to keep α relatively high. Keep testing assumptions, keep updating.
In stable environments, do not overreact to small anomalies. This is your low-α mode, relying on established routines and expertise (your default crystallised intelligence).
Train Working Memory for Bandwidth:
A stronger working memory capacity provides the ‘mental workspace’ to handle complex new rules and strategies without overloading. This is crucial in high‐α phases, when you are juggling multiple novel ideas or techniques. By training working memory (e.g. using Dual N‐Back - www.iqmidnware.com), you can maintain and integrate more information at once, making it easier to explore new approaches, track performance, and pivot between strategies. This extra bandwidth ultimately accelerates your path from creative exploration to stable mastery. But the training needs to be combined with learning systematic strategy use - as described in this article on learning and the previous blog on Bayesian belief updating.
Whether you are adjusting your plans on the fly or perfecting a new skill, the g loop is your built-in system for staying agile, resilient and smart. It provides a unified explanation for how we reason under uncertainty (Bayesian updating) and how we internalise new competencies (recursive skill learning).
Call to Action
Take a moment to reflect on your own learning processes. Are you pushing yourself enough to encounter ‘creative-level’ prediction errors when trying something new? Or do you tend to avoid them, letting α stay too low and stalling your progress? Can you spot areas in your life =- whether it is mastering a musical instrument, making investment decisions, navigating workplace challenges, or trying to understand economics and politics — where tuning your learning rate could accelerate growth or reduce wasted effort?
How best harness the g Loop insights? My suggestion: Train strategies like these while also training attetnion and working memory (capacity). This is the Strategy-Capacity Training approach to augmenting your IQ and strategic intelligence.

As you go about your day, remember: the g loop is humming away in the background, calibrating how much to update your beliefs and routines. By leaning into that mechanism - embracing the unexpected and capitalising on those error signals - you can become a more adaptive, strategic, and ultimately more intelligent version of yourself.
Thanks for reading, and stay tuned for more explorations into the g Loop - the broader Trident G theory it has been taken from - and their wide-ranging applications in cognitive science, AI, and beyond.
If you found this helpful, consider commenting, sharing, or subscribing.
References
Ashton Smith, Mark. (2024). Trident G Brain Training for Increasing IQ. IQ Mindware: Increase IQ Brain Training. Retrieved 15 March 2025, from https://www.iqmindware.com/far-transfer-brain-training/
Bansal, D. G. (2017, August 10). Deep Sleep Reinforces the Learning of New Motor Skills | UC San Francisco. https://www.ucsf.edu/news/2017/08/407981/deep-sleep-reinforces-learning-new-motor-skills
Donner, Y., Hardy, J.L. (2015). Piecewise power laws in individual learning curves. Psychonomic Bulletin Review, 22, 1308–1319. https://doi.org/10.3758/s13423-015-0811-x